目标站点:aHR0cHM6Ly93d3cubXBzLmdvdi5jbi9pbmRleC5odG1s
混淆样本可以通过扣代码或补环境的方式执行,本文不采用上述方案,只分享ast反混淆思路,供安全行业分析学习
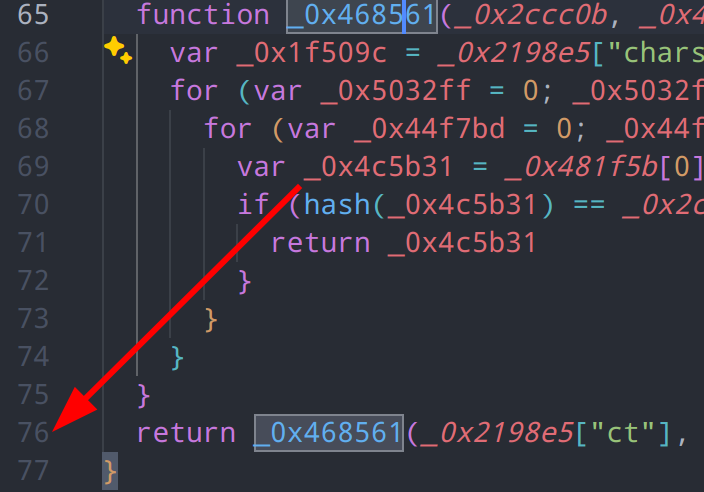
还原效果
本次混淆样例为经典的ob变种混淆,在请求网站时,会随机返回三种加密算法,通过babel的ast分析功能,我们可以动态的获取到反混淆后的js,原本样本1500行代码在反混淆后还原为76行,代码量减少了95%,还原了纯算算法
初步分析
打开某目标网站,发现加密参数
寻找一下具体的加密参数位置,将混淆代码dump下来,放入ide进行分析,可以看到,代码大致由5部分组成
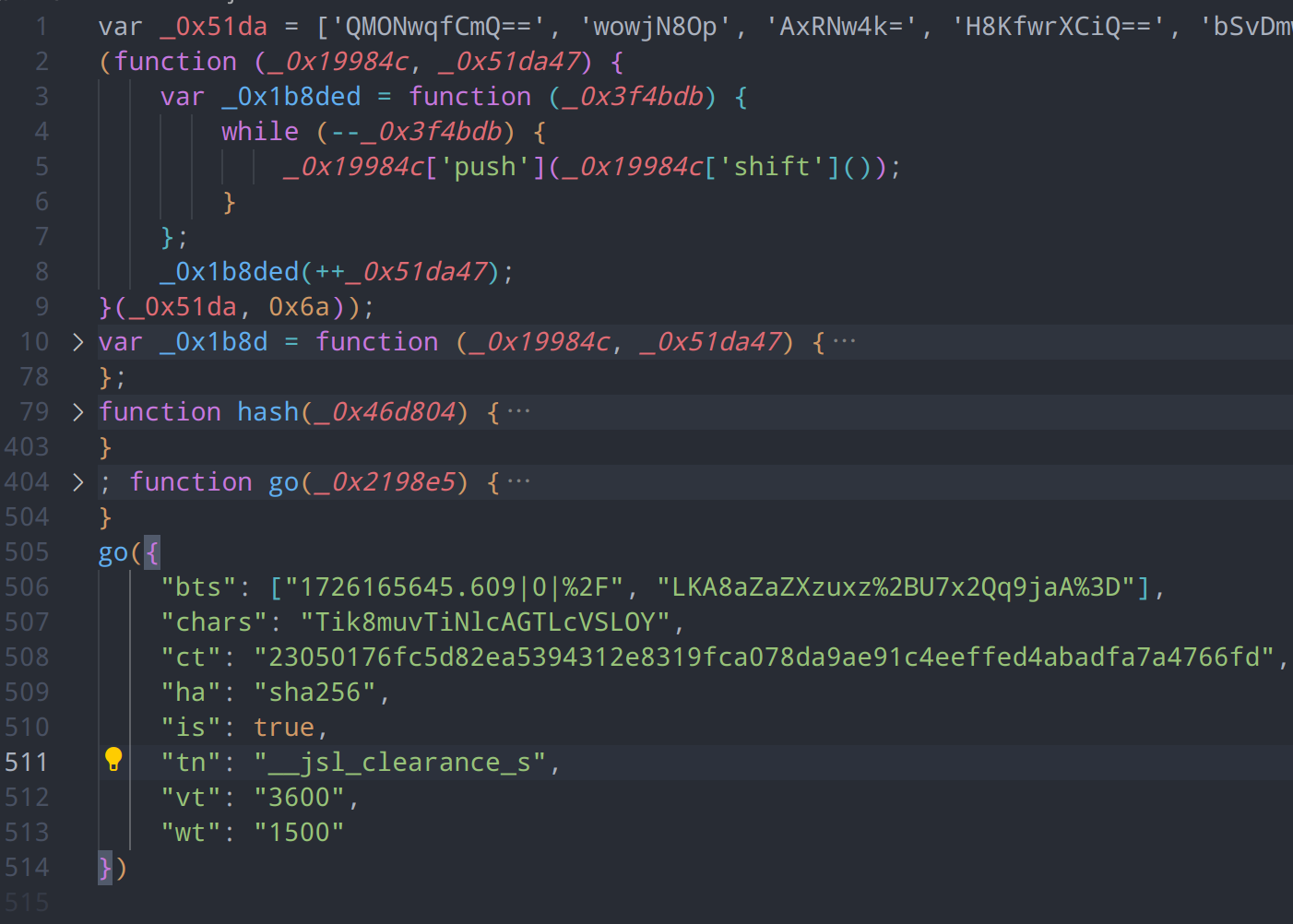
- 大数组:用于字符串加密混淆
- 自执行函数:用于将加密数组进行解密
- hash函数:用途非常明显,用于获取hash值
- 其他函数:用于具体加密逻辑
- 主函数入口go:用于执行传入的内容,并和浏览器api进行交互
这种字符串大数组+混淆的思路,基本上可以确定是ob混淆变种,我们反混淆的思路也很明确:获取解密后的字符串,回填常量,解除花指令混淆,删除死代码,最后还原整个流程
字符串解密
分析代码结构
从他的主函数go进入,可以发现首先声明了一个 _0x41e2c2 对象,随后对其成员进行了大量操作
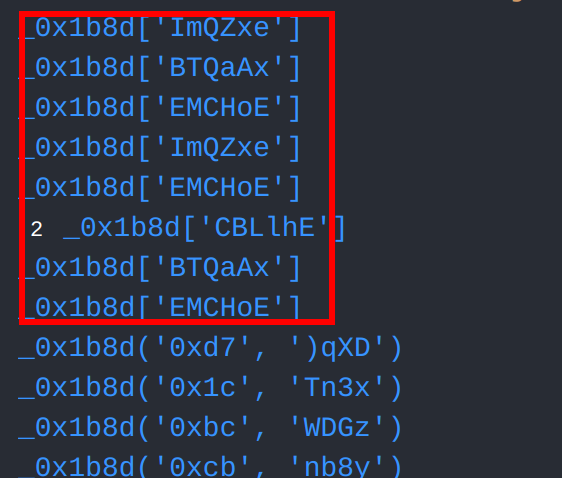
在使用方括号声明成员时,大量调用了_0x1b8d这个函数,说明 _0x1b8d 可能为字符串解密操作,
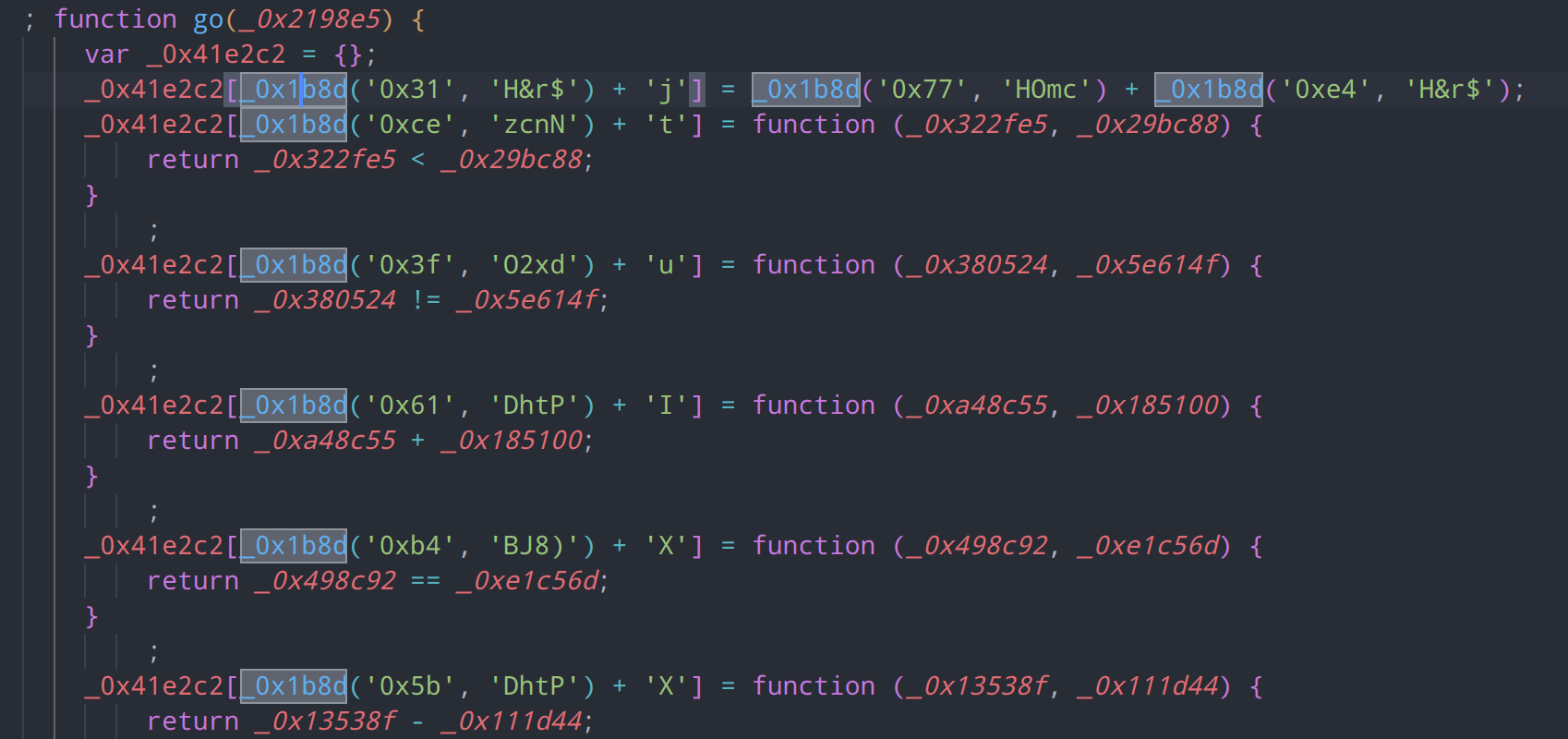
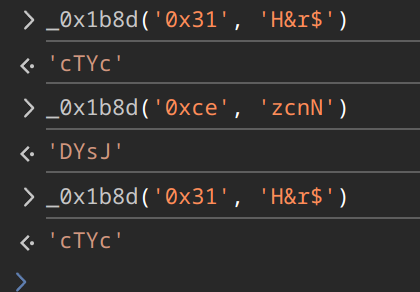
我们对这个函数进行一下测试,发现果然是字符串解密函数
console.log(_0x1b8d('0x31', 'H&r$'))
//输出:cTYc利用ide查看大数组引用,可以看到大数组仅在解密函数_0x1b8d中和另一个自执行函数中有所引用
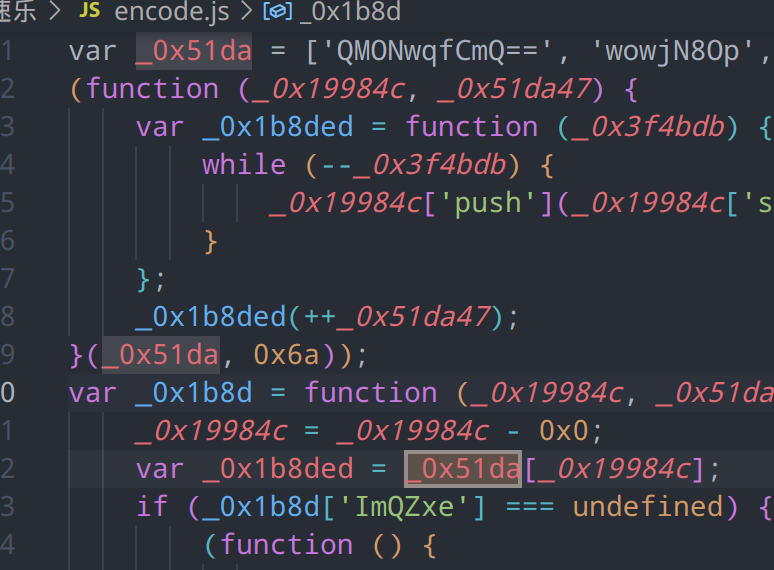
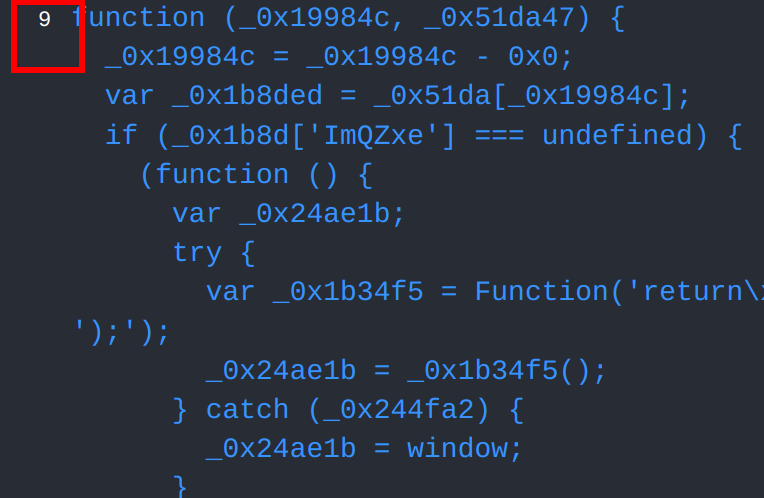
查看一下自执行函数,并没有任何外部引用,这段代码是一个典型的数组打乱片段,它的作用是对数组 _0x19984c 进行循环移位操作。具体来说,它会将数组中的元素向前移动若干位置,类似于一个环形缓冲区
(function (_0x19984c, _0x51da47) {
// 函数体
}(_0x51da, 0x6a));这是一个自执行函数,立即调用并传入两个参数 _0x51da 和 0x6a(十六进制的106)
var _0x1b8ded = function (_0x3f4bdb) {
while (--_0x3f4bdb) {
_0x19984c['push'](_0x19984c['shift']());
}
};这个函数接受一个参数 _0x3f4bdb,并在一个 while 循环中不断执行以下操作,直到 _0x3f4bdb 递减到0:
_0x19984c['shift']():移除数组_0x19984c的第一个元素并返回该元素。_0x19984c['push']:将移除的元素添加到数组_0x19984c的末尾。
_0x1b8ded(++_0x51da47);调用 _0x1b8ded 函数,并传入 _0x51da47 加1后的值(即107)。因此我们可以得知,这段代码的作用是将数组 _0x19984c 中的元素循环移位107次。每次移位操作将数组的第一个元素移到末尾,最终实现数组元素的重新排列。
判断解密操作是否幂等
在浏览器环境中将整个自执行函数复制,并反复执行字符串解密函数,发现输出结果一致,说明该字符串解密函数的执行操作幂等
在本地执行,发现生成结果和浏览器一致,那么说明这段代码并未进行环境检测,我们后续可以进行本地调试
还原流程
回过来观察一下我们需要解密的代码的特点,

可以得到以下还原思路
- 将本地的大数组打乱函数扣出执行,得到位置更改后的大数组
- 利用ast工具找到代码中
_0x1b8d的引用位置 - 将解密函数直接扣出,对代码中的字符串加密部分进行还原
- 拼接字符串常量
我们先利用ide的debugger工具,将大数组还原,并删除数组打乱自执行函数,将数组覆盖回代码
查看一下解密函数的定义
var _0x1b8d = function (_0x19984c, _0x51da47) {/.../}_0x1b8d 是一个变量定义的节点,且定义的标识符名称固定,我们利用这点找一下符合这个变量特征的引用
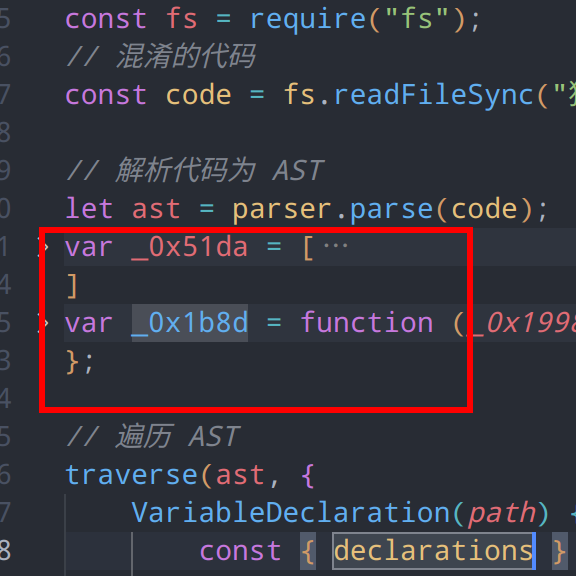
// 遍历 AST
traverse(ast, {
VariableDeclarator(path) {
const { id } = path.node;
// 节点为变量定义且标识符名称为_0x1b8d
if (id.name =='_0x1b8d') {
// 获取作用域下的引用
const binding = path.scope.getBinding(id.name);
if (binding && binding.constantViolations.length == 0) {
// 获取引用节点
for (const { parentPath } of binding.referencePaths) {
console.log(parentPath.toString());
}
}
}
}
},
);查看引用数量和ide中的数量是否相同,这里发现是相同的266个(ide中多出来的一个是变量定义)


执行反混淆模块输出一下,发现还包含了很多成员引用
将所有符合条件的成员引用的父函数打印,查看他们的引用位置
if (binding && binding.constantViolations.length == 0) {
for (const refPath of binding.referencePaths) {
const { parentPath } = refPath;
if (parentPath.isMemberExpression()) {
const functionPath = refPath.findParent(p => p.isFunction());
console.log(functionPath.toString());
}
}
}发现这9个成员表达式全都是在字符串解密函数 _0x1b8d 中的闭包函数中所引用,并未涉及外部作用域,因此在还原时可以直接忽略这些节点
将解密函数和大数组扣出,将扣出的解密函数和大数组放入ast反混淆模块中,以备使用。注意,原代码中的数组和解密函数不要手动删除,否则就无法获取变量的binding了,我们需要利用babel在反混淆过程中进行删除。
调用函数并替换节点
for (const refPath of binding.referencePaths) {
const { parentPath } = refPath;
if (parentPath.isCallExpression()) {
const args = parentPath.node.arguments;
const result = _0x1b8d(args[0].value, args[1].value);
parentPath.replaceWith(t.stringLiteral(result));
}
}删除大数组和解密函数
traverse(ast, {
VariableDeclarator(path) {
const { id } = path.node;
if (id.name == '_0x1b8d' || id.name == '_0x51da') {
path.parentPath.remove();
}
}
},);这样一来我们的代码就只剩下hash和主函数了

字面量还原
unicode、hex混淆还原
对于字符串和数字来说,还有多种混淆方式,如unicode和16进制混淆,这种字面量虽然不会影响代码执行,但是不具有可读性

遍历一下这些ast节点,可以看出他们[value]()值是已经是人类可读的值了,但和其他节点不同的是都含有一个人类不可读的extra.raw属性,因此我们可以修改extra属性来保证生成目标代码时为人类可读
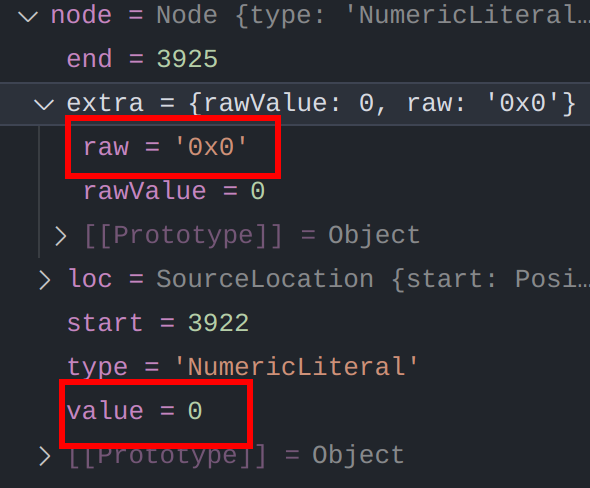
ast = parser.parse(generator(ast).code);
traverse(ast, {
StringLiteral(path) {
const node = path.node;
if (node.extra && /\\[ux]/gi.test(node.extra.raw)) {
try {
node_value = decodeURIComponent(escape(node.value));
} catch (error) {
node_value = node.value;
};
path.replaceWith(t.stringLiteral(node_value));
path.node.extra = { 'raw': JSON.stringify(node_value), 'rawValue': node_value };
}
},
NumericLiteral(path) {
if (path.node.extra ) {
path.node.extra.raw = path.node.value.toString();
}
}
},
);字符串合并、字面量还原
观察我们之前还原的字符串,很多都是需要拼接的,我们还需要让他合并一下
BinaryExpression: {
exit(path) {
if (path.node.operator === '+') {
const left = path.node.left;
const right = path.node.right;
if (t.isStringLiteral(left) && t.isStringLiteral(right)) {
const mergedString = left.value + right.value;
path.replaceWith(t.stringLiteral(mergedString));
}
}
}
}这样的话字符串节点就合并完成了

当然还有一种更简便的方式,可以直接利用babel的静态分析能力,计算出节点的值。对于可以通过静态分析求值的表达式,其执行结果也是幂等的,可以直接利用 path.evaluate 进行还原,不需要扣出代码并且这种方式适用于所有类型的表达式
// 静态计算
traverse(ast, {
"BinaryExpression|UnaryExpression"(path) {
const result = path.evaluate();
if (result.confident) {
path.replaceWith(t.valueToNode(result.value))
path.skip()
}
}
},
);花指令还原
成员归并
有很多类似这样的代码,通过将操作符提取为对象方法,从而加大我们的还原难度
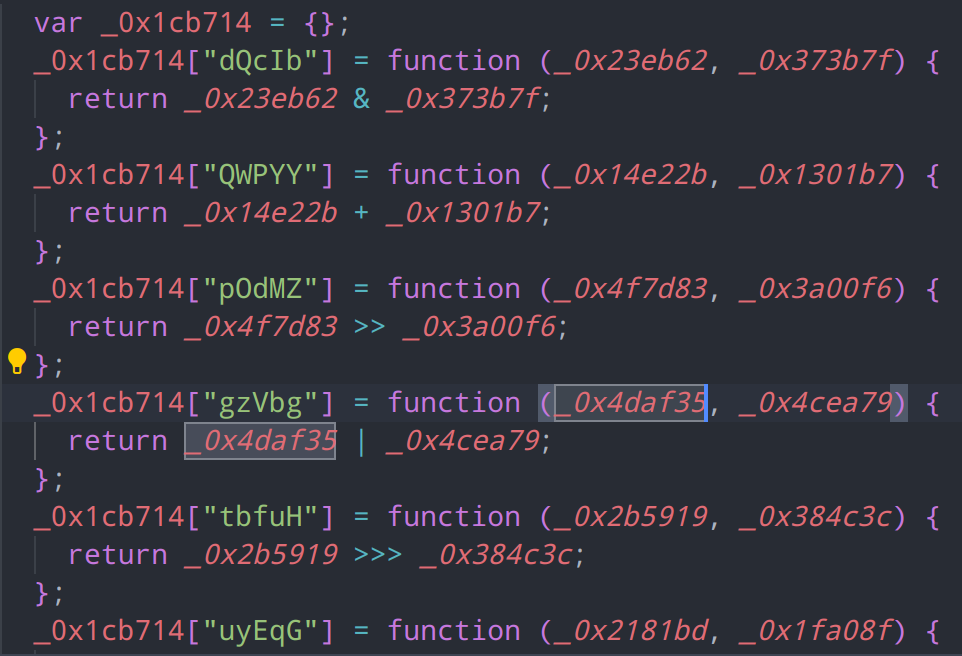
我们的目标是获取这些节点的引用,如果要获取引用,我们就需要获取对象的scope和binding,然后使用对象的属性节点去判断
然而,对于这种节点,其类型为AssignmentExpression,babel无法通过赋值表达式获取binding。花指令函数的节点是FunctionExpression,虽然babel支持从函数表达式获取binding,由于这是个匿名函数,也无法获取binding,因此我们需要先将这些函数移动至对象声明的内部,这样在后续处理时,我们就能够正常获取引用了
// 成员归并
const objectProperties = {};
traverse(ast, {
AssignmentExpression(path) {
const left = path.node.left;
const right = path.node.right;
// 检查是否是可以归并的成员类型
if (t.isMemberExpression(left) && t.isPureish(left.property) && t.isPureish(right)) {
const objectName = left.object.name;
const propertyName = left.property.value;
// 储存成员声明
if (!objectProperties[objectName]) {
objectProperties[objectName] = [];
}
const property = t.objectProperty(t.identifier(propertyName), right)
objectProperties[objectName].push(property);
path.remove();
console.log(generator(right).code)
}
path.scope.crawl();
},
});
traverse(ast, {
ObjectExpression(path) {
const { properties } = path.node;
const objectName = path.parent.id.name;
if (objectProperties[objectName]) {
properties.push(...objectProperties[objectName]);
}
path.scope.crawl();
}
});
合并后的效果是这样的
去除别名
还有一种方式会影响获取到变量的binding,即采用变量别名的方式,为一个对象添加多个别名,例如,下图中的_0x26c98a实则为_0x41e2c2的别名,如果不消除别名,那么我们就无法获取到花指令的所有引用位置并替换

检查是否是将一标识符赋值给新的变量,是的话就移除这个变量声明,并添加到别名映射表中。在下一轮遍历中对别名进行替换
// 变量别名替换
const aliasMap = {};
traverse(ast, {
VariableDeclarator(path) {
const id = path.node.id;
const init = path.node.init;
if (t.isIdentifier(init)) {
aliasMap[id.name] = init.name;
path.remove();
}
}
});
traverse(ast, {
Identifier(path) {
if (aliasMap[path.node.name]) {
path.replaceWith(t.identifier(aliasMap[path.node.name]));
}
}
});
成员花指令回填
我们需要找到对象引用之间的关系,从遍历 AST 中的 ObjectProperty 节点开始
- 检查节点的值是否是函数表达式
- 检查函数体是否是花指令
- 找到所有引用花指令的地方。
- 对每个引用路径按照参数进行替换
// 寻找所有引用花指令的地方
function getObscoreOpRefPath(path) {
const objectId = path.parentPath.parent.id;
const objectBinding = path.scope.getBinding(objectId.name);
const propertyName = path.node.key.name;
let opRef = [];
// 遍历所有引用路径,找到符合条件的引用
for (const refPath of objectBinding.referencePaths.reverse()) {
const memberExpression = refPath.parent;
if (!t.isMemberExpression(memberExpression)) continue;
const callExpression = refPath.parentPath.parent;
if (!t.isCallExpression(callExpression)) continue;
if (memberExpression.property.value !== propertyName) continue;
opRef.push(refPath.parentPath.parentPath);
}
return opRef;
}
// 替换操作
function replaceOperation(opRefPath, opExpression, params) {
const callExpression = opRefPath.node;
const args = callExpression.arguments;
let replacedExpression = t.cloneDeepWithoutLoc(opExpression);
// 替换相同名称的标识符以实现指令还原
params.forEach((param, index) => {
traverse(replacedExpression, {
noScope: true,
Identifier(innerPath) {
if (innerPath.node.name === param.name) {
innerPath.replaceWith(args[index]);
}
}
});
});
opRefPath.replaceWith(replacedExpression);
}
// 花指令替换
traverse(ast, {
ObjectProperty(path) {
const value = path.node.value;
if (!t.isFunctionExpression(value)) return;
const firstBodyStatement = value.body.body[0];
if (!t.isReturnStatement(firstBodyStatement)) return;
const opExpression = firstBodyStatement.argument;
const opRefPaths = getObscoreOpRefPath(path);
opRefPaths.forEach(opRefPath => {
replaceOperation(opRefPath, opExpression, value.params);
});
}
});回填后的效果如下,可以看到,对象调用混淆已经很少了
函数花指令回填
除了我们上面看到的普通的表达式花指令,还有一种这样的套娃函数
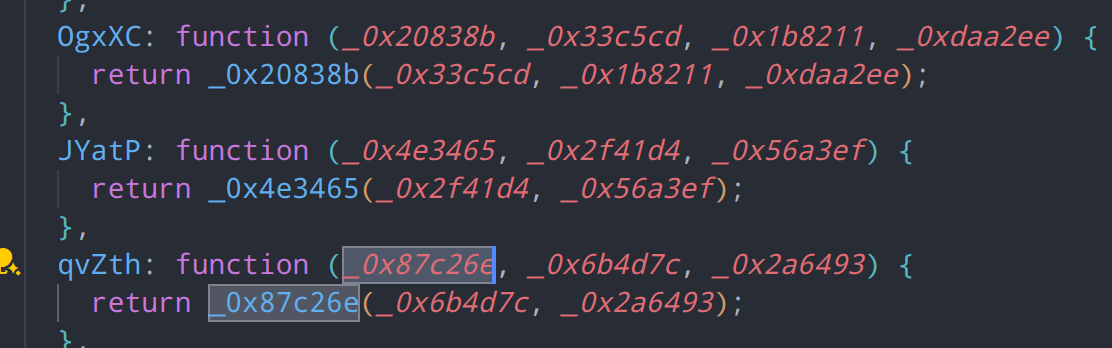
这种套娃函数是将普通的函数调用包装为两层,因此我们在将对象花指令还原过一次后,还需要对这种函数花指令再进行一次还原,如图,函数版的花指令并没有被消除

对象的花指令回填后便会引用这些函数版的花指令,我们将成员花指令替换的代码稍作修改,即可得到函数花指令替换版
// 函数型花指令替换
traverse(ast, {
FunctionDeclaration(path) {
const id = path.node.id;
const firstBodyStatement = path.node.body.body[0];
if (!t.isReturnStatement(firstBodyStatement)) return;
const opExpression = firstBodyStatement.argument;
const opRefPaths = path.scope.getBinding(id.name).referencePaths;
opRefPaths.forEach(opRefPath => {
if (!opRefPath.parentPath.isCallExpression()) return;
replaceOperation(opRefPath.parentPath, opExpression, path.node.params);
});
path.remove()
}
});处理过后,现在仅剩hash函数和主函数go,此外,hash函数中的闭包函数也仅剩下5个
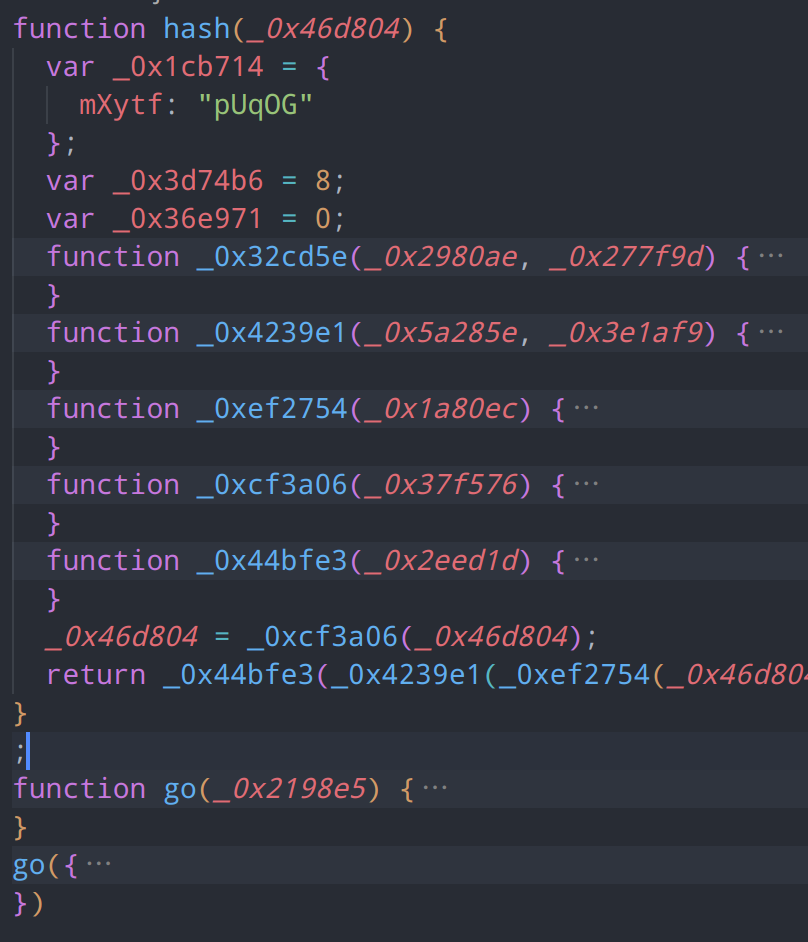
常量回填
此处还有一类内容我们可以处理,即下图的这种自声明后就从未变更过的变量,仅作为常量传递
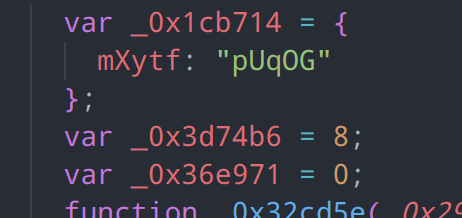
我们可以借助binding.constantViolations查看这个变量是否被修改,再使用binding.referencePaths寻找引用。refPath.evaluate().confident可以帮我们计算出,依据静态类型计算出的这个节点的值是否完全可信,之后我们就可以将这一类的变量删除了
traverse(ast, {
VariableDeclarator: {
exit(path) {
const { id, init } = path.node;
if (!t.isIdentifier(id) || !init) return;
const binding = path.scope.getBinding(id.name);
let refs_count = binding.references
if (!binding || binding.constantViolations.length > 0 || binding.references == 0) return;
binding.referencePaths.forEach(refPath => {
const result = refPath.evaluate()
if (result.confident) {
refPath.replaceWith(t.valueToNode(result.value));
refs_count--
}
});
if (refs_count == 0) {
path.remove()
}
path.scope.crawl();
}
},
MemberExpression: {
enter(path) {
const { object, property, computed } = path.node;
if (computed && t.isObjectExpression(object) && t.isStringLiteral(property)) {
const propName = property.value;
const prop = object.properties.find(p => t.isObjectProperty(p) && t.isIdentifier(p.key, { name: propName }));
if (prop) {
console.log(prop.value)
if (t.isStringLiteral(prop.value)) {
path.replaceWith(t.stringLiteral(prop.value.value));
} else if (t.isNumericLiteral(prop.value)) {
path.replaceWith(t.numericLiteral(prop.value.value));
}
}
}
path.scope.crawl();
}
}
});经过这上面的操作后,我们的这个节点

就变成了下面这样

代码量被大大缩减,我们再也不用面对一堆混淆乱码发呆了
控制流还原
控制流混淆是一种代码混淆技术,通过改变代码的执行路径和结构,使代码更难以理解和逆向:
- 插入无关代码:在代码中插入无关的或无用的代码片段,使得代码的逻辑变得复杂。
- 改变代码结构:将代码块拆分成多个部分,并通过条件语句、循环和跳转语句(如
goto)重新组织这些部分。 - 使用复杂的条件和循环:使用复杂的条件语句和循环来控制代码的执行路径,使得代码的逻辑变得难以跟踪。
原始代码
function add(a, b) {
return a + b;
}
console.log(add(2, 3));控制流混淆后的代码
function _0x1a2b(_0x3c4d, _0x5e6f) {
var _0x7g8h = 0;
while (true) {
switch (_0x7g8h) {
case 0:
var _0x9i0j = _0x3c4d + _0x5e6f;
_0x7g8h = 1;
break;
case 1:
return _0x9i0j;
}
}
}
(function() {
var _0x1m2n = [2, 3];
console.log(_0x1a2b(_0x1m2n[0], _0x1m2n[1]));
})();控制流的特点是,原始代码被分割为多段内容,然后执行一个大循环,循环内部由流程控制语句(if或swich,甚至是短路运算)控制代码逻辑,通过指令数进行跳转,从而打乱原始的代码逻辑
现在,我们还剩最后,也是最长的一段需要还原的部分了,看一下下面这段代码的结构,很明显就是我们所说的控制流
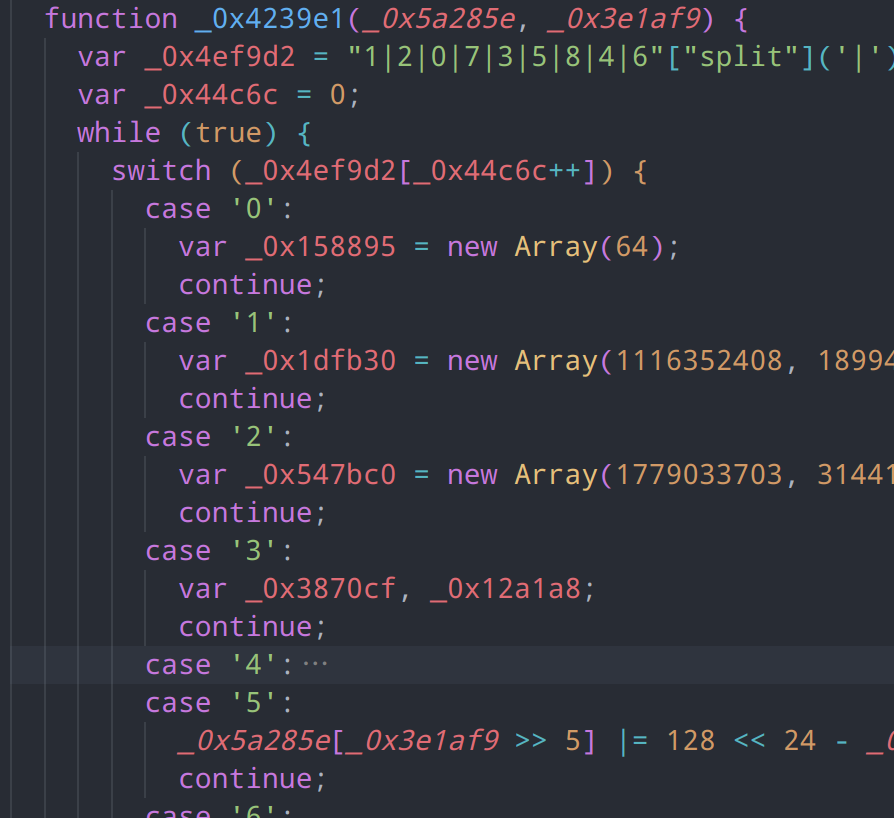
实际上在这个例子中,这是应该是最简单的控制流了,手动还原的速度要远远大于ast还原。但是在其他的大型网站中,控制流往往是千级甚至万级,并且穿插着混淆和跳转,因此在这里学习ast还原方法,将大大有助于我们日后的工作
仔细观察代码,该控制流的指令由_0x4ef9d2控制,通过split进行切分,然后传入到switch中,由_0x4ef9d2[_0x44c6c++]决定执行哪一条指令。switch外部有一个while循环,每循环一次,switch就会执行一条指令,并通过_0x44c6c++将指令的指针移到下一条。
因此我们的还原思路是
- 将switch中每个分支的代码块都抽取出来
- 将操作数和代码块之间建立映射表
- 根据
_0x4ef9d2所代表的操作指令,重建整个代码块 - 将重建的代码替换掉函数体
先将所有的case节点dump出来,注意,此处的控制流中,每条case后都跟有continue,需要将continue语句移除
// 控制流还原
const switchCases = {};
traverse(ast, {
SwitchStatement(path) {
// 从switch中提取控制流的代码块
for (const { test, consequent } of path.node.cases) {
for (const statement of consequent) {
if (t.isContinueStatement(statement)) {
break
}
if (!switchCases[test.value]) {
switchCases[test.value] = []
}
switchCases[test.value].push(statement)
}
}
}
});根据操作数和case代码块的对应关系,重建控制流
// 重建代码
traverse(ast, {
VariableDeclarator(path) {
// 获取控制流操作数
const { id } = path.node;
if (id.name === "_0x4ef9d2") {
const init = path.get("init")
// 获取控制流操作数,重建控制流
const controlFlow = eval(init.toString())
const restoredBlock = [];
for (const test of controlFlow) {
restoredBlock.push(...switchCases[test])
}
// 替换函数体
const functionParent = path.getFunctionParent()
functionParent.get("body").replaceInline(restoredBlock)
path.stop()
}
},
})
还原成果
经过了上面的反混淆后,我们成功将代码由1200行降到了150行,这对于逆向来说提高了不止十倍的效率,下面我们就可以对仅剩的函数内容进行分析了,通过人工分析,进一步削减代码数量并还原出加密逻辑

主函数还原
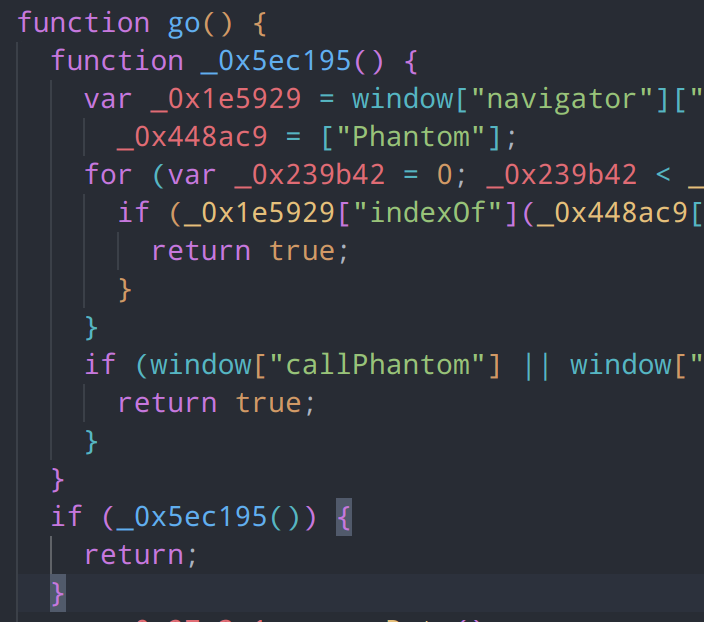
环境检测
我们先从主函数go入手,go中的_0x5ec195 对浏览器navigator、window等对象实施检测,如果检测到非浏览器环境则返回true,并在下方跳出主函数,使参数生成逻辑不能正常进行,我们对此处可以直接进行删除操作
主函数cookie生成
继续向下查看,发现_0x417549就是我们生成的参数,这个数组内始终有数据,因此可以将else分支也移除掉
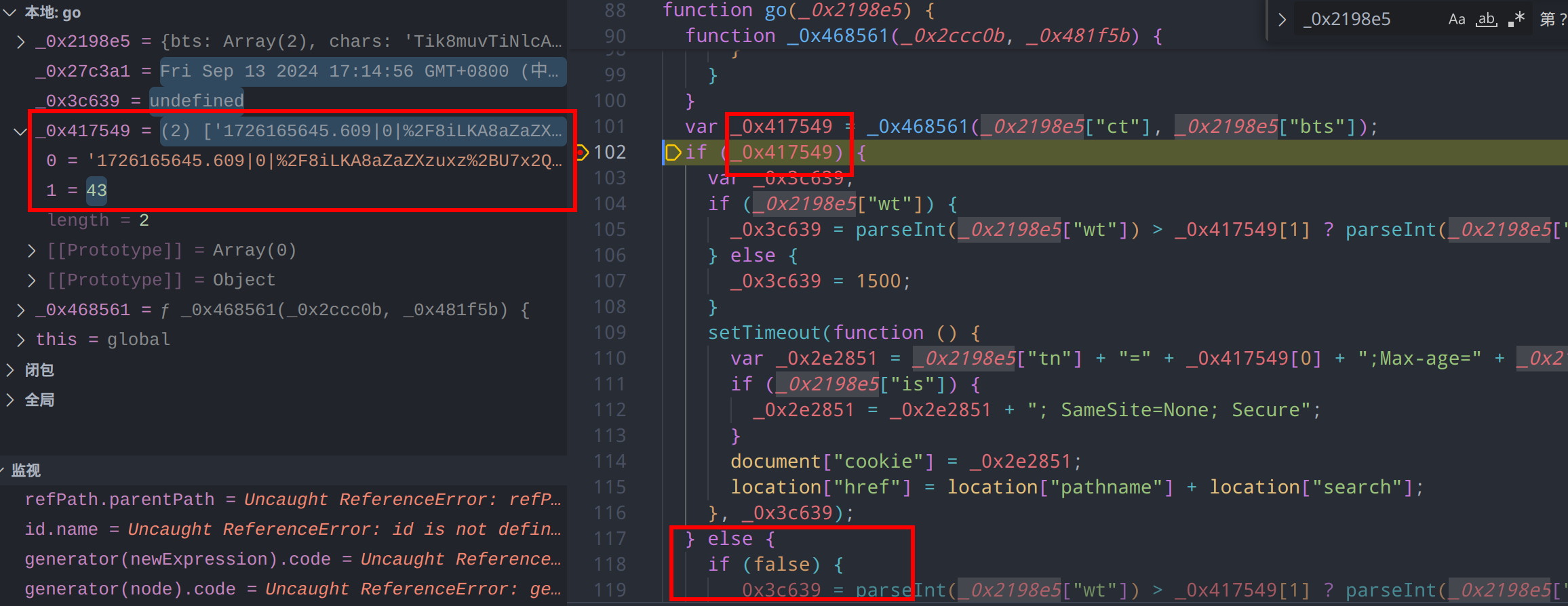
进入if分支内查看,前几行主要是生成了一个 _0x3c639 参数,用于执行计时器,执行完毕后,主函数函数体直接结束,这个参数除了用于计时器延时执行以外没有任何引用,因此可以判断是一个无用参数,可以直接删除掉这段内容并将计时器中的代码块提出来
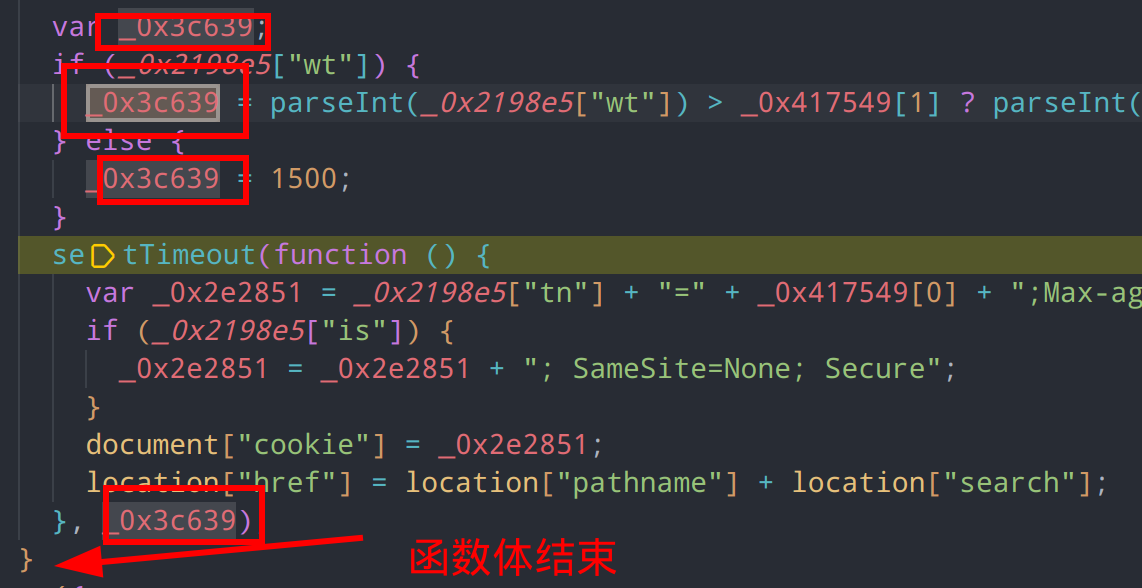
合并代码后,思路就很清晰了,剩余的代码作用是从主函数的参数中提取部分字段,和我们之前获取到的加密参数之间进行拼接,最后得到结果,更新cookie后跳转页面
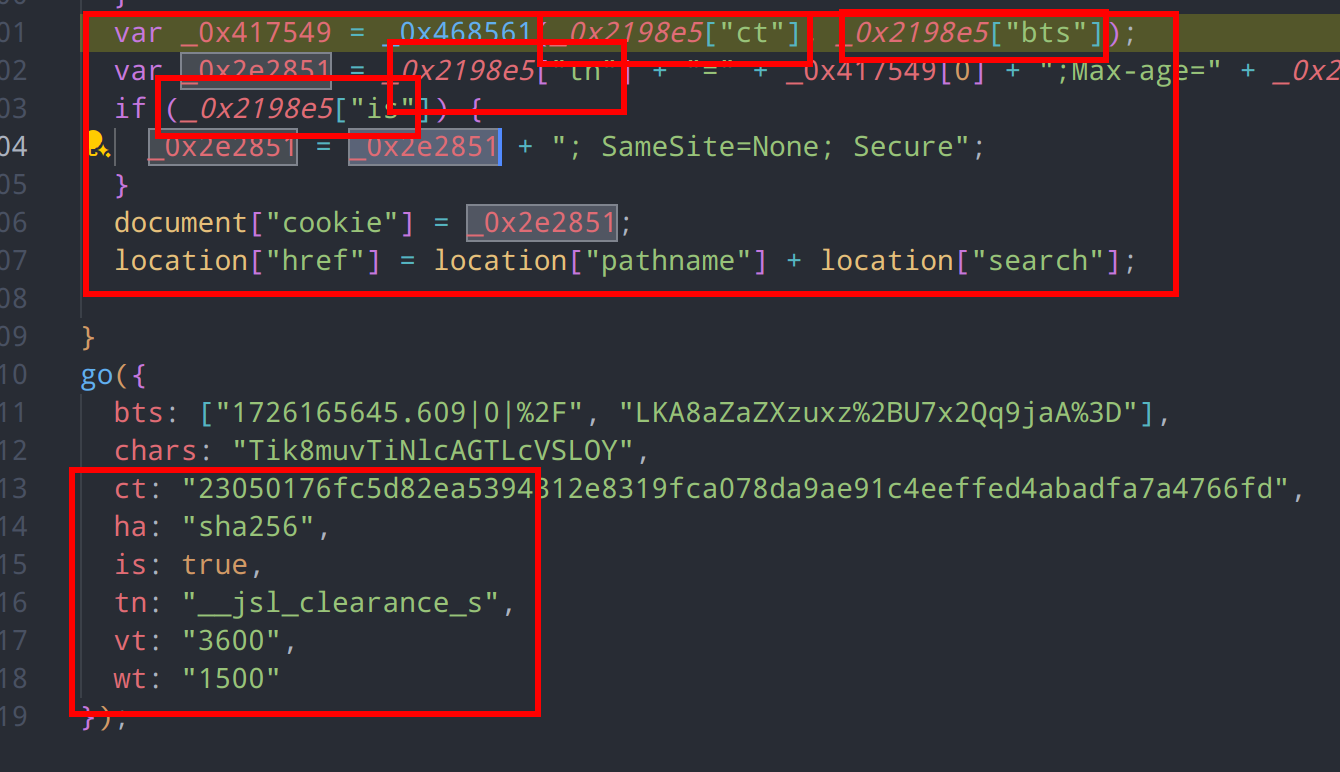
回到这个cookie生成的函数中,返回的第二个参数没有任何引用,并且仅为时间差计算,因此可以判断属于无效输出,主要输出内容为_0x4c5b31,从整个函数结构来看,其作用是尝试生成所有可能的字符串组合,并计算它们的哈希值,直到找到一个匹配的哈希值。这属于pow工作量证明的一种方式,用于验证哈希值
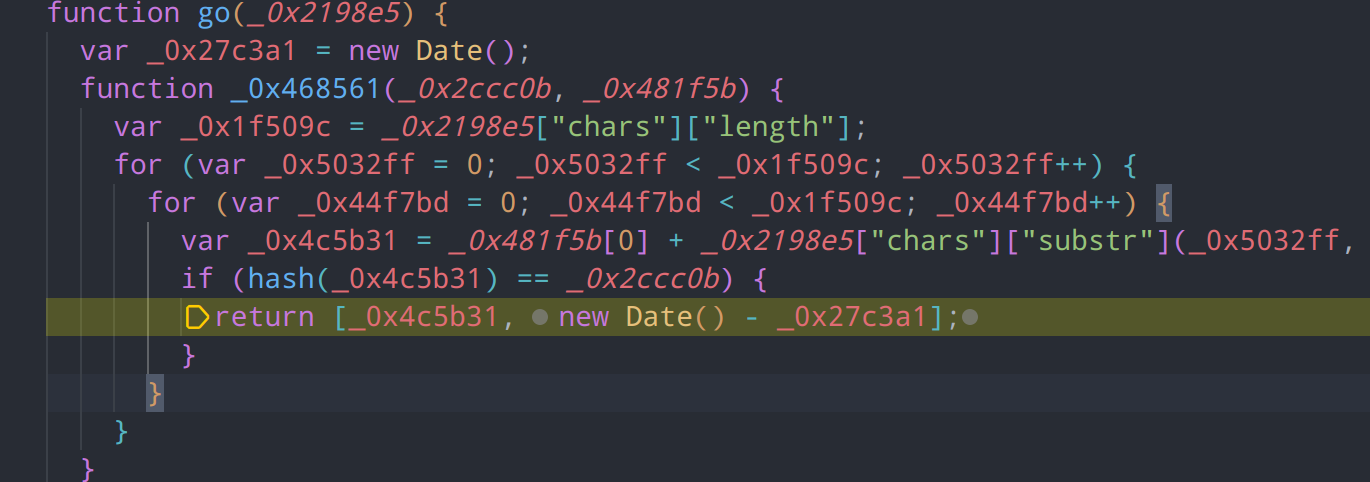
主函数还原后内容
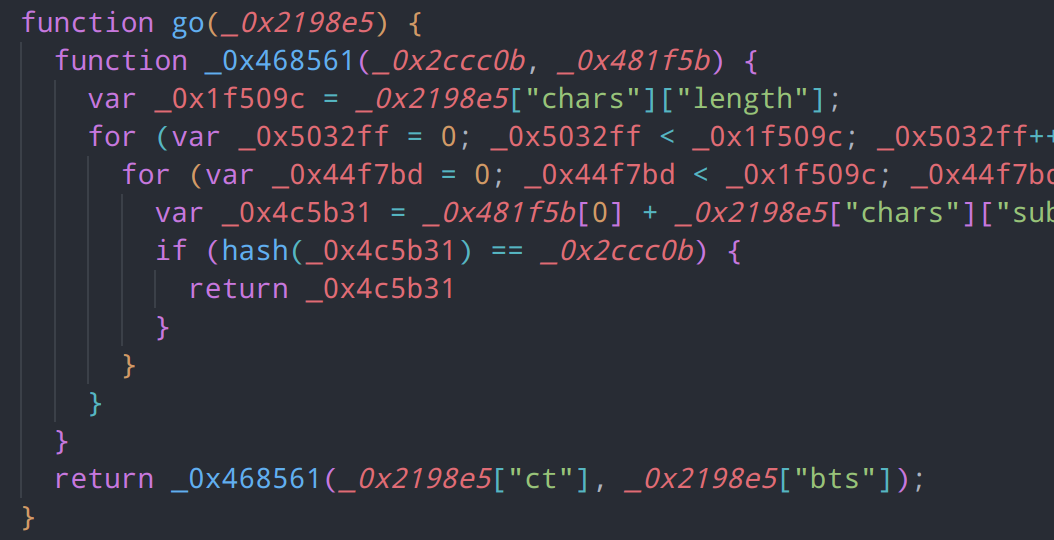
哈希函数分析
hash函数内部共有5个函数
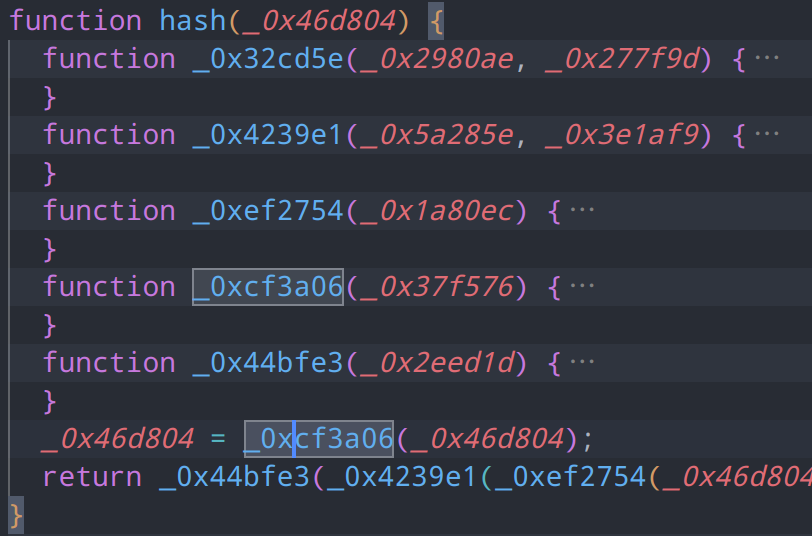
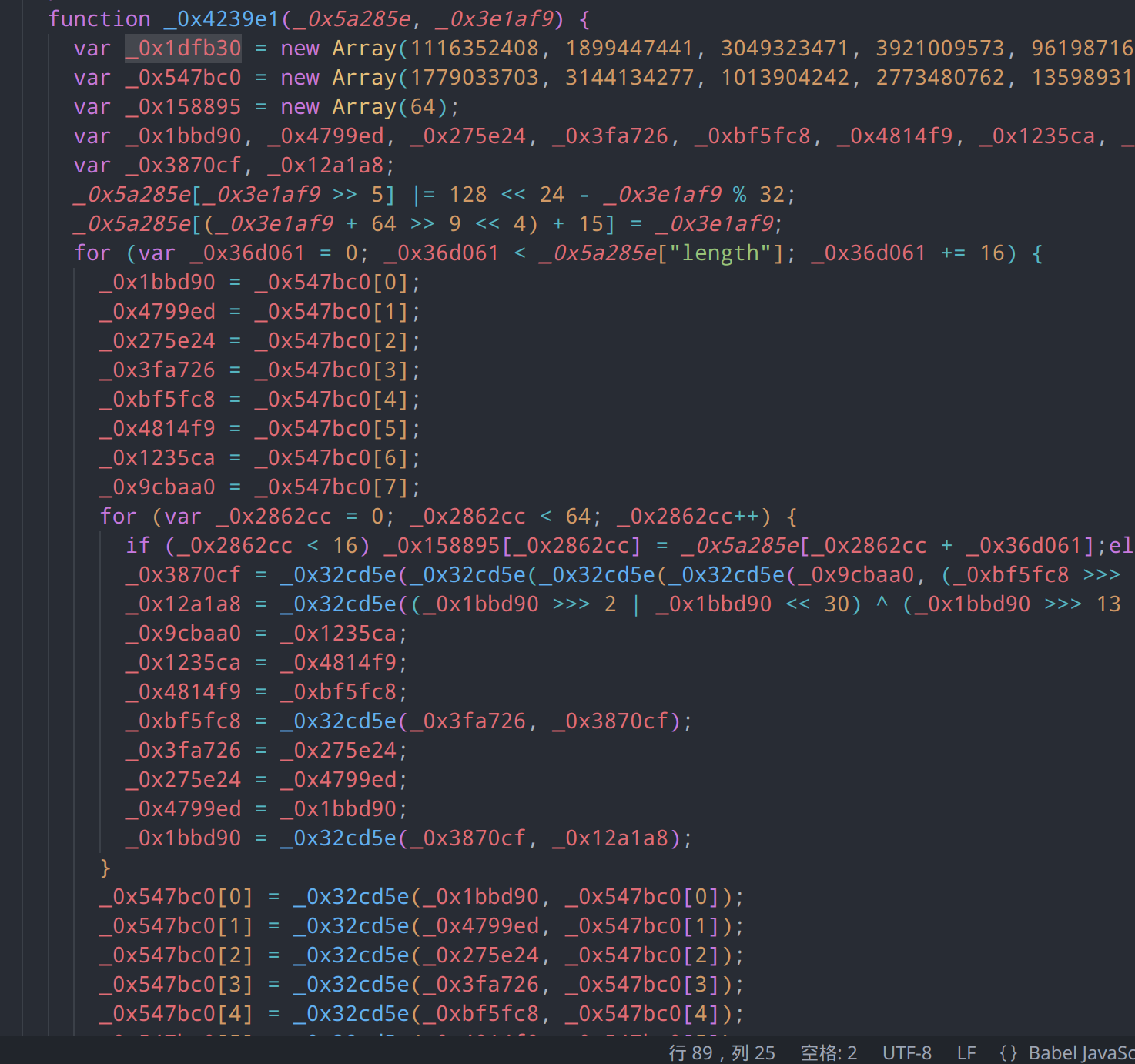
32位整数模拟
经典的哈希算法都是最初由c语言编写的,对于各种加密函数,其内部也是含有一定的c语言特征的。例如我们的第一个闭包函数
function _0x32cd5e(_0x2980ae, _0x277f9d) {
var _0x31c1c1 = (_0x2980ae & 65535) + (_0x277f9d & 65535);
var _0x156de1 = (_0x2980ae >> 16) + (_0x277f9d >> 16) + (_0x31c1c1 >> 16);
return _0x156de1 << 16 | _0x31c1c1 & 65535;
}对于c语言来说,16位int上限的大小仅为65536,此处用了大量的magic number进行位运算和移位操作,可以联想到是在对整数溢出在处理。由于js为动态类型语言,所以是肯定支持大整数的,此处对整形溢出做处理,以和c语言特性一致。具体来说,它在模拟 32 位无符号整数的加法运算,并处理可能的溢出情况。
低 16 位相加:
var _0x31c1c1 = (_0x2980ae & 65535) + (_0x277f9d & 65535);将两个 32 位整数的低 16 位相加,并存储在变量
_0x31c1c1中。65535是十六进制的0xFFFF,用于屏蔽高 16 位,只保留低 16 位。高 16 位相加:
var _0x156de1 = (_0x2980ae >> 16) + (_0x277f9d >> 16) + (_0x31c1c1 >> 16);将两个 32 位整数的高 16 位相加,并加上低 16 位相加后的进位(如果有)。
>> 16用于将整数右移 16 位,从而获取高 16 位。组合结果:
return _0x156de1 << 16 | _0x31c1c1 & 65535;将高 16 位和低 16 位组合成一个 32 位整数。
_0x156de1 << 16将高 16 位左移 16 位,_0x31c1c1 & 65535保留低 16 位,然后使用按位或运算符|将它们组合在一起。
通过模拟 32 位无符号整数的加法运算,来实现类似于 C 语言中的整形溢出效果。它将两个 32 位整数的低 16 位和高 16 位分别相加,并处理可能的溢出情况,然后将结果组合成一个新的 32 位整数。
字符串分块编码
第二个函数传入了我们需要加密的字符串,将输入字符串转换为一个整数数组return出来,数组的每个整数表示字符串的 32 位块,实现了分块编码功能
function _0xef2754(_0x1a80ec) {
var _0xb30bef = Array();
for (var _0x222989 = 0; _0x222989 < _0x1a80ec["length"] * 8; _0x222989 += 8) {
_0xb30bef[_0x222989 >> 5] |= (_0x1a80ec["charCodeAt"](_0x222989 / 8) & 255) << 24 - _0x222989 % 32;
}
return _0xb30bef;
}_0x1a80ec["charCodeAt"](_0x222989 / 8)获取字符串中第_0x222989 / 8个字符的 ASCII 码。& 255确保只保留字符的低 8 位。<< 24 - _0x222989 % 32将字符的二进制数据左移到正确的位置。_0x222989 >> 5计算当前字符属于数组中的哪个整数(每个整数包含 32 位,即 4 个字符)。|=将二进制数据存储在数组中的相应位置。
utf8编码
第三个函数,进行了大量的字符串操作,并且在我们测试下,传入的英文会原样传出,而中文则会被编码,其中一样包含了许多magic number,例如ASCII 字符(0-127)、双字节字符(128-2047)、三字节字符(2048 及以上),因此这个函数是一个utf8编码函数。由于我们传入的cookie只会是ascii英文字符串,因此可以直接删除此函数
function _0xcf3a06(_0x37f576) {
var _0xb9a176 = new RegExp("\n", "g");
_0x37f576 = _0x37f576["replace"](_0xb9a176, "\n");
var _0xb2fac = "";
for (var _0x1d9308 = 0; _0x1d9308 < _0x37f576["length"]; _0x1d9308++) {
var _0x2bc062 = _0x37f576["charCodeAt"](_0x1d9308);
if (_0x2bc062 < 128) {
_0xb2fac += String["fromCharCode"](_0x2bc062);
} else if (_0x2bc062 > 127 && _0x2bc062 < 2048) {
if (true) {
_0xb2fac += String["fromCharCode"](_0x2bc062 >> 6 | 192);
_0xb2fac += String["fromCharCode"](_0x2bc062 & 63 | 128);
} else {
return x & y ^ ~x & z;
}
} else {
_0xb2fac += String["fromCharCode"](_0x2bc062 >> 12 | 224);
_0xb2fac += String["fromCharCode"](_0x2bc062 >> 6 & 63 | 128);
_0xb2fac += String["fromCharCode"](_0x2bc062 & 63 | 128);
}
}
return _0xb2fac;
}十六进制转换
函数使用一个 for 循环遍历 _0x2eed1d 数组的每一个元素。循环的范围是 _0x2eed1d 数组长度的四倍,这意味着每个数组元素将被处理四次。
在循环体内,代码通过 charAt 方法从字符串 "0123456789abcdef" 中提取相应的十六进制字符。位运算部分 _0x1a73b7 >> 2 和 (3 - _0x1a73b7 % 4) * 8 用于确定当前处理的字节和位位置,& 15 操作则确保只取出当前字节的低四位,通过位运算和字符串操作将每个整数转换为十六进制字符。
function _0x44bfe3(_0x2eed1d) {
var _0x4c87b6 = "";
for (var _0x1a73b7 = 0; _0x1a73b7 < _0x2eed1d["length"] * 4; _0x1a73b7++) {
_0x4c87b6 += "0123456789abcdef"["charAt"](_0x2eed1d[_0x1a73b7 >> 2] >> (3 - _0x1a73b7 % 4) * 8 + 4 & 15) + "0123456789abcdef"["charAt"](_0x2eed1d[_0x1a73b7 >> 2] >> (3 - _0x1a73b7 % 4) * 8 & 15);
}
return _0x4c87b6;
}sha256
从他传入的代码中,可以看出当前使用的是sha256

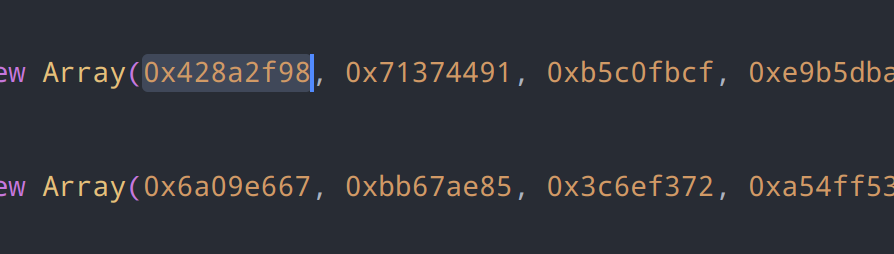
常量数组:
var _0x1dfb30 = new Array(...); var _0x547bc0 = new Array(...);数组包含了 SHA-256 算法中使用的常量值。
_0x1dfb30包含了 64 个常量值,_0x547bc0包含了 8 个初始哈希值。主循环:
for (var _0x36d061 = 0; _0x36d061 < _0x5a285e["length"]; _0x36d061 += 16) { ... for (var _0x2862cc = 0; _0x2862cc < 64; _0x2862cc++) { ... } }实现了 SHA-256 的主循环,处理每个 512 位的消息块。
实际上,代码其余部分还实现了 SHA-256 的消息填充、消息调度和压缩函数。

好厉害,我想给大佬口一下
objectBinding.referencePaths.reverse() 成员花指令还原的时候,直接对原绑定数组进行reverse会影响原数组导致如果再次遍历这个数组的时候顺序会乱吧
确实应当使用toReversed替换reverse方法。不过objectBinding.referencePaths没有顺序上的要求,并且是一个浅克隆的数组,对数组容器进行修改不会影响实际ast操作
有相关源码吗大佬
这几天才开始看 AST ,看下来获益良多。希望大佬多多分享,让我们多学点😄
顺着大佬思路滤了一遍,比我自己写的好太多了,膜拜大佬,以及撸代码时遇到一些小问题:
还原流程部分的代码:id.name =='_0x1b8d' 是否应为id.name ==='_0x1b8d' 花指令还原->成员归并部分:console.log(generate(right).code)是否应为console.log(generator(right).code) 再次膜拜大佬,祝大佬爆更O~O已经很久没有搞过web了,印象中babel在不同的命名空间下,generator和generate都是存在的,二者的效果一致,取决于你从哪个模块引用