提示:右下角可以点击查看目录
流程分析
我们之前在 cloudflare逆向(3)js请求 中分析了他的请求流程,在js加密流程中,主要分为这四步:
- 预处理:在第一个页面的script标签中进行初始化,主要围绕window._cf_chl_opt进行,并加载初始的反爬脚本
- 第二步:向
/cdn-cgi/jsch/v1?ray=::rayId::发送初始GET请求,获取经动态混淆的加密脚本 - 第三步:获取另一个post请求的加密内容,并加载进当前页面进行环境检测
- 通过生成的md、r、sh等参数,获取获取5s盾的cookie,最后可携带cookie请求真实网页
第一个预处理js,可从script标签中提取出来,(function(){...})();表示立即执行该匿名函数,仅做一些初始化工作,因此不需要过多解读
(function() {
window._cf_chl_opt = {
cvId: '3',
cZone: "paoluz.link",
cType: 'non-interactive',
cNounce: '31152',
cRay: '8bdafe9fbcf0099b',
cHash: '8530c6de9e8c3dc',
cUPMDTk: "\/?__cf_chl_tk=coi3.ydg2.eGDziNfk7QyQegh9ZiKQ.0O4QZQIb5Ys8-1725421608-0.0.1.1-7572",
cFPWv: 'g',
cTTimeMs: '1000',
cMTimeMs: '120000',
cTplV: 5,
cTplB: 'cf',
cK: "",
fa: "\/?__cf_chl_f_tk=coi3.ydg2.eGDziNfk7QyQegh9ZiKQ.0O4QZQIb5Ys8-1725421608-0.0.1.1-7572",
………
}());从第二步开始,我们可以将解密工作分为三层,第一层就是如下的代码了,约为5600行+。可以看出大量使用了花指令和字符串加密,如果直接使用扣代码或人肉跟栈分析,难度较大
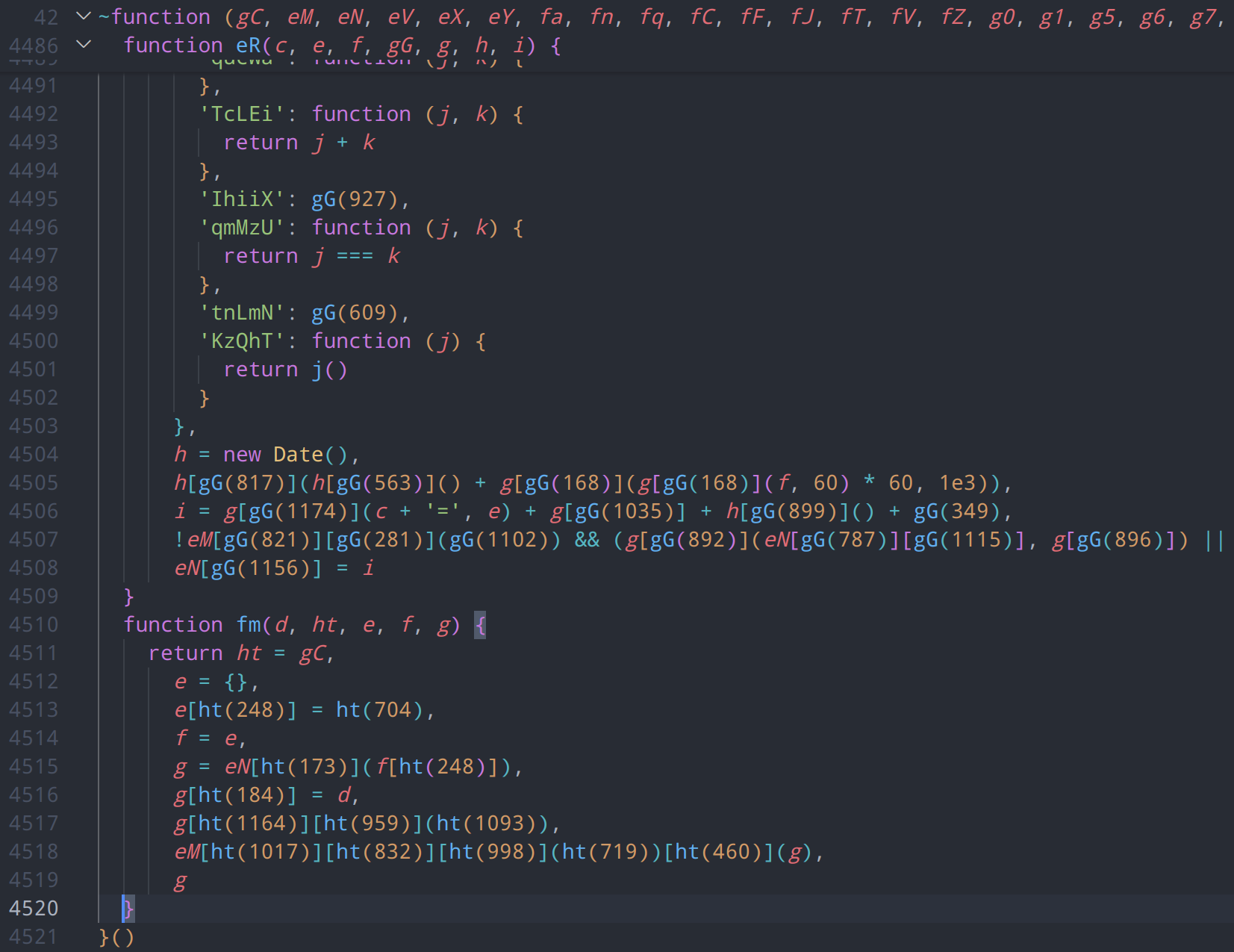
通过对原始文件的分析,我们可以确定cloudflare使用了多种混淆技术,包括但不限于:
- 变量名混淆:使用无意义的变量名
- 字符串混淆:对字符串进行混淆和解码,使得字符串内容不易被直接可读
- 控制流:移除原有的
if节点,使用复杂的switch和while循环结构实现跳转,代替顺序逻辑 - 死代码插入:插入看似有用实则无用的代码片段,加大逆向工作量
- 花指令:将运算符抽取为函数,让加减乘除也变得不可读
- 内联函数:将函数定义嵌入到其他函数中,将多个函数合并成一个复杂的函数,使得函数的实际用途难以辨别。
这些混淆技术的目的是增加代码的复杂性,使得逆向工程和理解代码变得更加困难,不过好在一层的代码量较少,初学者进行ast分析时可以快速查看到当前的结果。不ast可以帮我们解除大量的混淆,但是在去混淆后,我们仍然要进行逆向分析,在学习ast还原前,一定要掌握好js基础和逆向技巧,仅仅使用ast是不够的。
花指令还原
既然说ast无法一步到位,那我们为什么要多做这一步呢?直接扣代码和补环境不好吗?
做ast分析第一步,我们要先观察一下整个js整体的加密情况,然后按照难易程度对相对应的加密方式进行排列,这样才能先从简易的地方下手,还原出我们需要的内容
随便翻两下,从60行开始,发现这里将一些双目运算符提取出来了,这是一种最基础的花指令方式,与2023年的5s盾不同的是,以前是将所有的花指令集中存放,而2024是将这样的代码分散于各处,例如这里仅有3个指令,而其他的花指令则是被隐藏到了不同的对象中
'CsuEb': function (g, h) {
return g + h
},
'HJrLT': function (g, h) {
return g * h
},
'nlhGX': function (g, h) {
return g << h
}想象一下,1+2*3变成了obj.HJrLT(obj.CsuEb(0,1),obj.HJrLT(3,2))时,阅读起来该有多崩溃
我们可以用ast先检查一下都有哪里调用了这些,如何检查呢?
第一步,我们首先要提取出节点的特征,可以看出,5s的花指令特征还较为简单,普遍为函数套一个return,我们可以检测函数节点下的ReturnStatement是否包含BinaryExpression等节点
function isObfuscatedFunction(node) {
if (node.type === 'FunctionExpression' && node.body.body.length === 1) {
const statement = node.body.body[0];
if (statement.type === 'ReturnStatement') {
const argument = statement.argument;
return ['BinaryExpression', 'LogicalExpression', 'UnaryExpression'].includes(argument.type);
}
}
return false;
}之后我们需要遍历所有节点,并输出符合特征的节点,这里有个小技巧,在 Babel 的 AST 中,ObjectProperty节点表示对象字面量中的属性,用于描述对象中的键值对。例如,在下面这个例子里,CsuEb 就是 ObjectProperty节点。通过遍历ObjectProperty,能大量减少节点数量,加快反混淆程序的运行速度。
const obj = {
'CsuEb': function (g, h) {
return g + h
}
};言归正传,利用我们之前编写的isObfuscatedFunction检查一下节点
const obfuscatedFunctions = [];
traverse(ast, {
ObjectProperty(path) {
const node = path.node;
if (node.value.type === 'FunctionExpression') {
if (isObfuscatedFunction(node.value)) {
const code = generate(node).code;
obfuscatedFunctions.push(code);
}
}
}
});输出一下看看结果:仅仅是这样的简单节点总计就有283个,而这样的节点每个占3行,也就是说,在还未进行还原,而仅仅删除花指令这一项混淆操作的情况下,就能够减少800多行使原代码量至少缩减1/5。如果我们将ObjectProperty替换为"FunctionDeclaration|FunctionExpression|ArrowFunctionExpression",那么数量预计还能接着增加,可见ast对于我们的逆向有多大的帮助
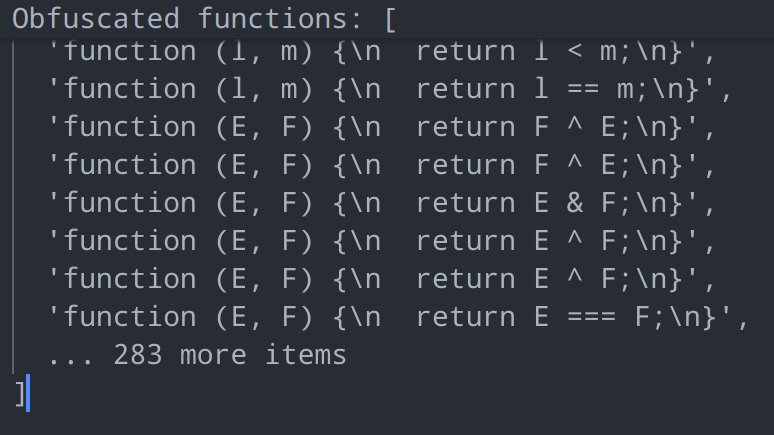
当找到了对应的节点后,我们只需要将return中的节点替换为传入的实参,然后替换掉对应的节点即可,有些情况下,花指令可能会嵌套多层,需要多次进行替换,需要注意的是,在2024版的5s盾中,还需要额外对超长标识符字符串先进行回填,才能够处理掉花指令
标识符还原(2024)
2024年开始,5s盾增加了一种将标识符、属性收集在一个字符串中的混淆方案,因此不能直接用旧有的反混淆插件。不过其类似之前的字符串加密大数组还原,和旧版不同的是,这种方式是作为一种变体出现的,使用字符串和spllit进行分割后还原至js代码中,长度大多在3000字符以上,如果不对这个长字符串进行还原的话,是无法还原花指令的
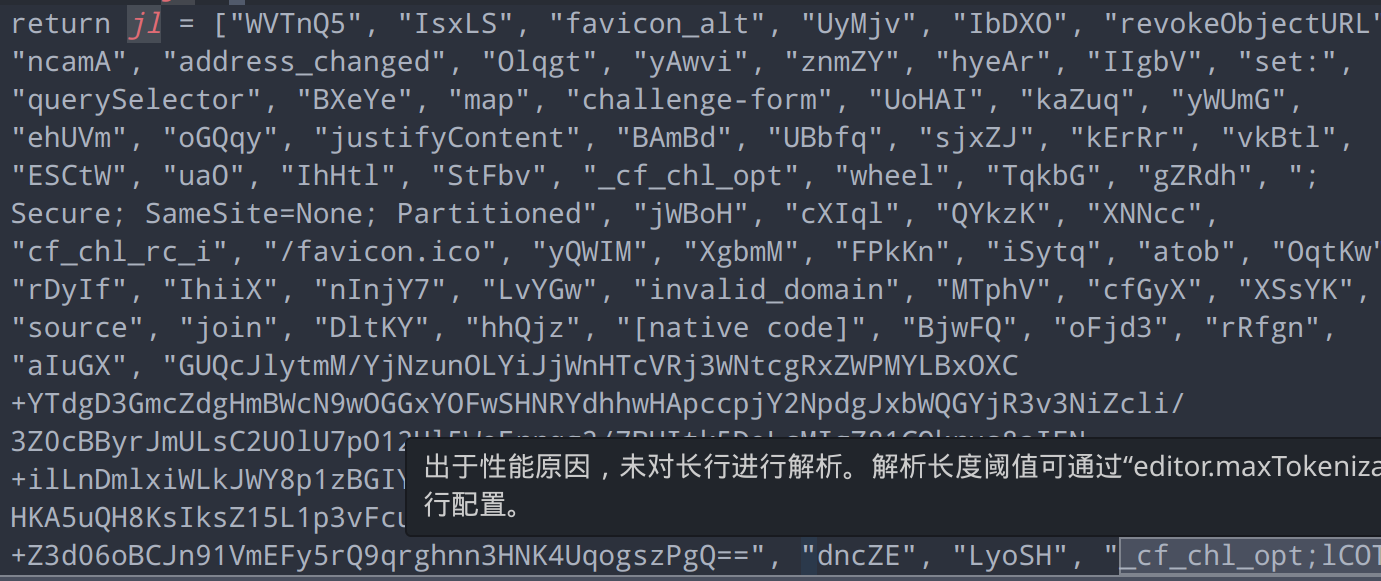
return jl = 'WVTnQ5,IsxLS,favicon_alt,revokeObjectURL .....,set:,querySelector'.split(',')提取一下特征:左侧为字符串常量,右侧为split,且split里也是常量,这种情况下,表达式的执行结果肯定也是常量,因此我们可以利用这个特性进行还原
// 遍历AST并替换特定节点
traverse(ast, {
CallExpression({ node }) {
if (
types.isStringLiteral(node.callee.object) &&
node.callee.property.name === 'split' &&
types.isStringLiteral(node.arguments[0])
) {
// 替换节点为split的结果
const splitResult = node.callee.object.value.split(node.arguments[0].value);
const elements = splitResult.map(value => types.stringLiteral(value));
path.replaceWith(types.arrayExpression(elements));
// 生成注释,以便于我们定位观察
path.addComment('leading', 'split', true);
}
}
});还原效果如下
自执行函数解密
将大数组回填前需要先看一下全文是否有多种这样的数组,并且要查看一下还原前结构
经过查看整个全文就只有一个jl变量被用作字符串大数组,并且这个a函数实际上为花指令变形,返回值就是jl自身,那么我们可以将所有a的调用处替换为jl数组
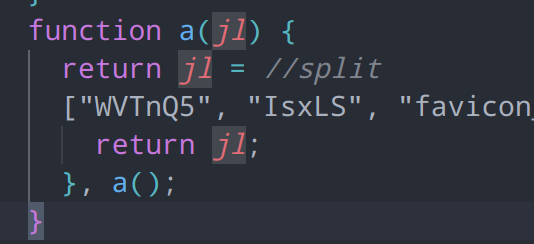
查看一下这个关连大数组的函数,发现其是一个自执行函数,且把我们的大数组生成函数作为参数传入,然后自执行,同来打乱jl数组的顺序。自执行函数有个特点,传入的参数都是固定的,我们可以简单把形参和实参相对比然后传入
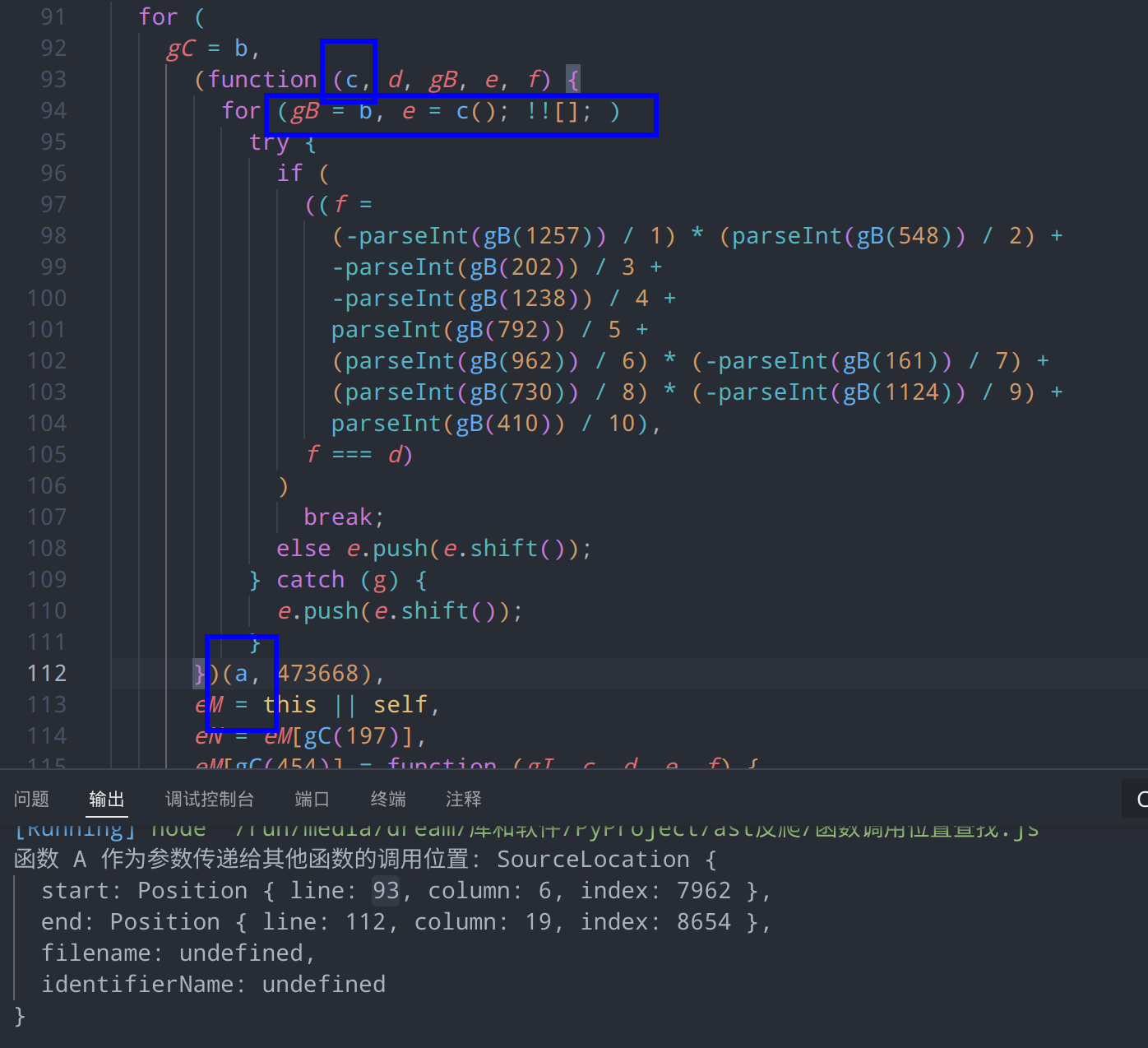
不过,由于js允许形参和实参不必一一对应,我们需要检测传入的实参是否匹配
- 检查是否是带参自执行函数,而不是函数或方法调用:对于每个
CallExpression节点,检查其callee是否是一个函数表达式(FunctionExpression),并且是否有传入参数。 - 建立形参与实参的映射:遍历函数表达式的形参,将其与对应的实参建立映射关系,存储在
params_map中。 - 替换形参为实参:如果当前节点不是函数声明的形参,并且对应的实参节点不是自执行函数,则将当前节点替换为对应的实参节点。
- 移除函数参数: 将原来的调用表达式替换为新的函数调用表达式,实参列表为空。
// 遍历 AST 并查找自执行函数调用
traverse(ast, {
CallExpression(path) {
const callee = path.node.callee;
const args = path.node.arguments;
const params_map = {};
// 检查是否是自执行函数调用,并检测参数是否传入
if (
types.isFunctionExpression(callee) &&
args.length > 0 &&
args.length <= callee.params.length
) {
callee.params.forEach((param, index) => {
if (param.type === "Identifier" && args[index]) {
params_map[param.name] = args[index];
}
});
const functionBodyPath = path.get("callee.body");
// 遍历函数体,替换形参为实参
functionBodyPath.traverse({
Identifier(innerPath) {
// 判断当前节点是否是函数声明的形参
const isFunctionParam =
innerPath.parentPath.isFunction() &&
innerPath.parent.params.includes(innerPath.node);
const argNode = params_map[innerPath.node.name];
// 判断当前节点是否是自执行函数
const isSelfCalledFunction = types.isCallExpression(argNode);
// 如果有实参传入,并且当前节点不是函数声明的形参,则替换形参
if (argNode && !isFunctionParam && !isSelfCalledFunction) {
const argIsVarOrLiteral = argNode.name || argNode.value;
console.log(
innerPath.node.loc.start.line,
":",
innerPath.node.name,
"->",
argIsVarOrLiteral
);
innerPath.replaceWith(argNode);
}
},
});
// 移除函数参数
callee.params = [];
// 替换调用表达式为新的函数表达式
path.replaceWith(types.callExpression(callee, []));
}
},
});执行一下,发现替换了不少形参,通过将自执行函数的形参替换为实参,可以自执行函数,不仅仅是为了使代码更易读、更易理解,如果自执行函数的参数均转化为字面量后,可以直接将当作表达式执行,从而减少大量的代码。
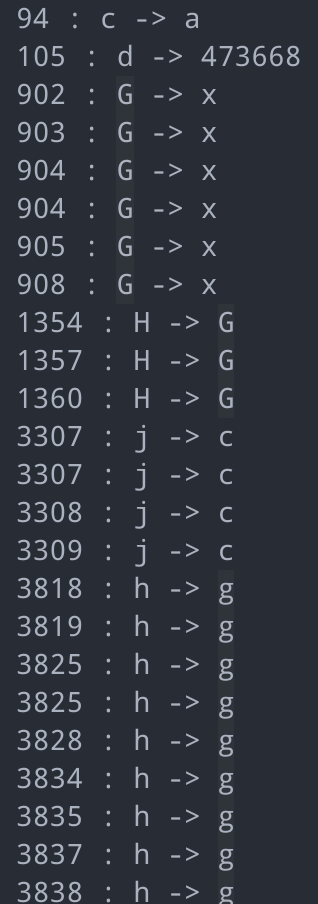
可以看到,还原以后,5个形参和2个实参都被消除了,这时我们可以就直接将a()的值简单替换为jl数组了
常量折叠
jsfuck源于一门编程语言brainfuck,其主要的思想就是只使用8种特定的符号来编写代码,它使用了()+[]!这几个字符组合来编写代码,例如(!![]+[])[+[]]实际上的值为字母t
!![] // true 变形为 (true+[])[+[]]
!![]+[] // "true" 变形为 ("true")[+[]]
+[] // 0 最终变形为 ("true")[0]而cloudflare也使用了这些混淆手段,例如,根据js的特性!![]对应的值在这里实际为true
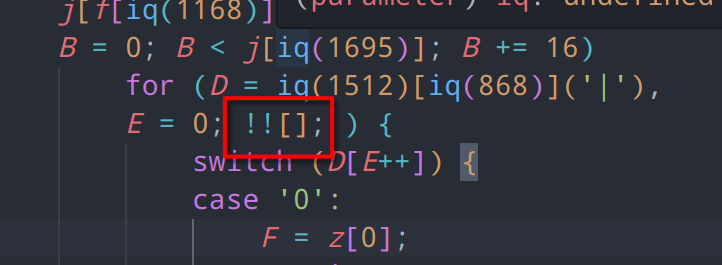
另一种较为简单的混淆视听的表达式,即通过将普通的常量值变为常量运算来增加阅读难度,例如false变为!1,或将一个简单的数字变为一长串加减乘除运算
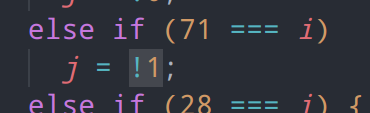
这类表达式也有类似的特征,我们可以利用常量折叠的编译原理来消除这些难以阅读的部分,将其替换为常量,具体操作是对常量表达式调用path.evaluate()直接计算出表达式的值,然后进行替换
function isConstantFoldable(path) {
const { confident, value } = path.evaluate();
if (!confident)
return;
if (typeof value == 'number' && (!Number.isFinite(value))) {
return;
}
return true;
}
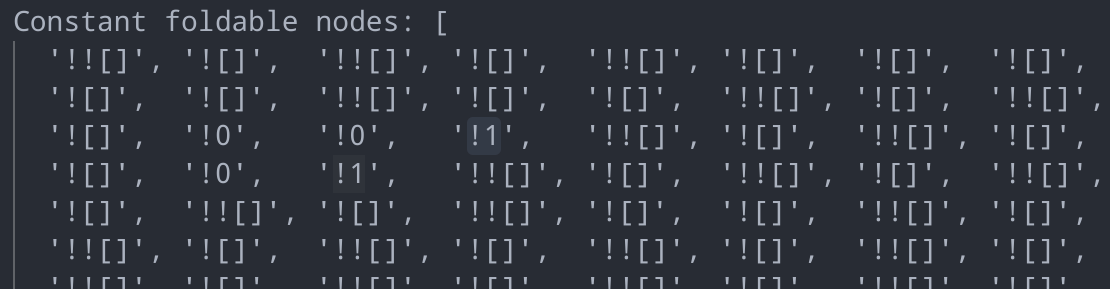
const constantFoldableNodes = [];
traverse(ast, {
"BinaryExpression|UnaryExpression"(path) {
if (isConstantFoldable(path)) {
constantFoldableNodes.push(generate(path.node).code);
}
}
});简单寻找一下,发现了大量的jsfuck
还有一种节点是void开头的表达式,对于void节点,也可以直接处理成为0
字符串字面量还原
对于16进制或unicode的字符串,我们也要去做一下处理,将其还原为可读类型,这一步可以放在所有的反混淆操作都进行完成之后进行。不过,在国内经常见到的16进制混淆,到了cloudflare变成了不值一提的操作,变得非常罕见。。。。
traverse(ast, {
NumericLiteral({ node }) {
if (node.extra && /^0[obx]/i.test(node.extra.raw)) {
simplifyLiteralNodes.push(node)
}
},
StringLiteral({ node }) {
if (node.extra && /\\[ux]/gi.test(node.extra.raw)) {
simplifyLiteralNodes.push(node)
}
},
})条件表达式还原
条件表达式也就是我们熟知的三目运算,有很多a ? b : c;类型的表达式,这些实际上是被混淆后出现的,我们需要将其还原为if代码块,以便于理解,例如:
n ? a ? b : c : d;实际上为
if (n) {
if (a) {
b;
} else {
c;
}
} else {
d;
}需要注意的是,我们还需要额外对条件表达式的父节点进行检测,因为父节点如果不是表达式语句,可能是以下几种特殊情况:
- 声明语句:例如变量声明 、函数声明、类声明等。
- 控制流语句:例如
if语句、for循环、while循环、switch语句等。
当出现这种情况时,说明原代码调用了条件表达式的值,如果直接进行节点替换,那么很可能就丢掉了节点,因此需要提前判断。
在还原时,如果consequent或alternate不是表达式语句,则应当将其包装在一个BlockStatement({}代码块)中。这样可以确保在转换为if语句时,consequent和alternate都是有效的代码块。
traverse(ast, {
ConditionalExpression(path) {
let { test, consequent, alternate } = path.node;
const ParentPath = path.parentPath;
if (types.isExpressionStatement(ParentPath)) {
if (!types.isExpressionStatement(consequent)) {
consequent = types.BlockStatement([
types.ExpressionStatement(consequent),
]);
}
if (!types.isExpressionStatement(alternate)) {
alternate = types.BlockStatement([
types.ExpressionStatement(alternate),
]);
}
ParentPath.replaceInline(types.IfStatement(test, consequent, alternate));
}
},
});成员归并
继续寻找,可以找到大量这类的节点
gq[i9(1699)] = i9(1061),
gq[i9(1192)] = i9(703),
gq[i9(1249)] = i9(691),
gq[i9(1499)] = i9(1341),
gq[i9(322)] = i9(663),
gq[i9(1722)] = i9(698),
gq[i9(662)] = i9(690),
gq[i9(1640)] = i9(1015),
gq[i9(1175)] = i9(404),
gq[i9(430)] = i9(909),
gq[i9(1050)] = i9(665),其基本操作是将成员提取出来,使ide的语法工具无法直接找到成员定义,这样即使借助ide也难以进行定向。
这一类的就比较难以理解了,看起来比较复杂,然而实际上比较简单,这里我们需要先分析一下,写一个最小例子:
let obj = {
a: 1
};
obj.b = 2;
obj.c = 3;我们需要还原成为这样:
let obj = {
a: 1,
b: 2,
c: 3
};这样看思路就比较明确了,我们只需要两步操作:
识别对象字面量的赋值:
- 代码首先检查赋值表达式的左侧是否是标识符,操作符是否为 "=",右侧是否是对象表达式。
- 如果满足条件,则提取对象的名称和属性列表。
合并后续的属性赋值:
- 获取当前赋值表达式的所有后续兄弟节点。
- 遍历这些兄弟节点,检查它们是否是赋值表达式,且左侧是成员表达式,右侧是字符串字面量。
- 如果满足条件,则将这些属性添加到对象字面量的属性列表中,并移除这些兄弟节点。
const collectKeyAndValueOfObject = {
AssignmentExpression({ node, parentPath }) {
// 检查父节点是否是表达式语句
if (!parentPath.isExpressionStatement({ expression: node })) return;
const { left, operator, right } = node;
// 检查赋值表达式的左侧是否是标识符,操作符是否为 "=",右侧是否是对象表达式
if (!types.isIdentifier(left) || operator !== "=" || !types.isObjectExpression(right)) return;
// 获取所有后续兄弟节点
parentPath.getAllNextSiblings().some(nextSibling => {
if (!nextSibling.isExpressionStatement()) return true;
const expression = nextSibling.get('expression');
if (!expression.isAssignmentExpression({ operator: "=" })) return true;
const { left, right } = expression.node;
if (!types.isMemberExpression(left)) return true;
const { object, property } = left;
if (!types.isIdentifier(object, { left.name }) || !types.isStringLiteral(property)) return true;
// 将属性添加到对象字面量中
right.properties.push(types.ObjectProperty(property, right));
nextSibling.remove();
});
},
};控制流还原
控制流混淆是一种通过改变代码的执行路径来增加代码复杂性和难以理解性的技术,例如,你可以从cloudflare的代码中找到大量的控制流,控制流过程一般也有其固定的格式,例如本段代码的控制流就是for-switch控制流
for (M = hh(1139)[hh(229)]('|'),
N = 0; !![];) {
switch (M[N++]) {
case '0':
return !![];
case '1':
O = e[hh(173)](hh(704));
continue;
case '2':
O.id = hh(969);
continue;
case '3':
f[hh(1017)][hh(832)][hh(998)](K[hh(440)])[hh(460)](O);
continue;
case '4':
O[hh(241)][hh(697)] = hh(268);
continue
}
break
}我们需要将其原本的
let a = someFunction();
for (; true;) {
switch (a++) {
case 0:
code_0();
continue;
case 1:
code_1();
continue;
case 2:
code_2();
break;
}
break;
}还原为
code_0();
code_1();
code_2();思路是大致三步
- 检查
for语句的测试条件是否为true字面量,检查for语句主体的第一个语句是否是switch语句,第二个语句是否是break语句。 处理
switch语句:- 获取
switch语句的所有case语句。 - 根据
for (M = hh(1139)[hh(229)]('|')表达式中的调度数组(通过|分隔的字符串)来确定执行顺序。 - 遍历调度数组,根据索引获取相应的
case语句并合并到缓存节点中。 - 如果
case语句的最后一个语句是continue语句,则将其移除。
- 获取
替换
for语句:- 用合并后的语句替换
for语句。 - 移除当前的赋值表达式语句。
- 用合并后的语句替换
AssignmentExpression(path) {
//控制流判断
const { node, parentPath } = path;
if (!parentPath.isExpressionStatement({ expression: node })) return;
const { left, operator, right } = node;
if (!types.isIdentifier(left) || operator !== "=" || !types.isCallExpression(right)) return;
const nextSibling = parentPath.getNextSibling();
if (!nextSibling.isForStatement()) return;
const { test, body } = nextSibling.node;
if (!types.isLiteral(test, { value: true }) || body.body.length !== 2) return;
const [switchNode, breakNode] = body.body;
if (!types.isSwitchStatement(switchNode) || !types.isBreakStatement(breakNode)) return;
// 开始还原
const { cases } = switchNode;
const disPatchArray = right.callee.object.value.split("|");
let retBody = [];
disPatchArray.forEach(index => {
const caseBody = cases[index].consequent;
if (types.isContinueStatement(caseBody[caseBody.length - 1])) {
caseBody.pop();
}
retBody = retBody.concat(caseBody);
});
//替换节点
nextSibling.replaceWithMultiple(retBody);
parentPath.remove();
}死分支代码删除
在代码混淆过程中,死代码(Dead Code)指的是那些在程序执行过程中永远不会被执行的代码。这些代码通常是通过某些逻辑条件(如恒为 true或 false 的条件语句)被故意插入到代码中的,以增加代码的复杂性和混淆程度,从而使得逆向工程和代码分析变得更加困难。
if (false) {
console.log("永远不会执行");
} else {
console.log("永远执行");
}if (false) 语句块中的代码永远不会被执行,因为条件 false永远不会为真。因此,console.log("This will never run"); 就是死代码。当然,实际还原时,例子肯定不会这么简单,例如,if语句嵌套逗号表达式,再嵌套条件表达式,就问你看的懂吗:

第一步:直接移除空语句节点
最简单的一集,实际上这步是最后执行的
EmptyStatement(path) {
path.remove();
}第二步:评估测试条件
这里要注意一点,就是需要把所有的常量、字符串、花指令之类的回填了,再进行这一步,不然很多if条件没办法计算出真假
另外要记得ConditionalExpression也是可以出现死代码的
"IfStatement|ConditionalExpression"(path) {
let { consequent, alternate } = path.node;
let testPath = path.get('test');
const testEvaluation = testPath.evaluateTruthy();
}第三步:对if语句块或者条件表达式块进行取舍
这里的代码需要插入到第二步的代码块中
if (testEvaluation === true) {
if (types.isBlockStatement(consequent)) {
consequent = consequent.body;
}
path.replaceWithMultiple(consequent);
} else if (testEvaluation === false) {
if (alternate != null) {
if (types.isBlockStatement(alternate)) {
alternate = alternate.body;
}
path.replaceWithMultiple(alternate);
} else {
path.remove();
}
}这样处理后,我们的代码就会只保留有用的语句了
死返回语句删除
有多个return语句的函数,也可以进行处理,不过这里需要谨慎处理,因为有可能第一个return语句并没有执行,并且这种状况多见,以下给一个简单的例子,不考虑这种情况
FunctionExpression(path) {
const { node } = path;
let returnCount = 0;
// 遍历函数体,统计return语句的数量
path.traverse({
ReturnStatement(innerPath) {
returnCount++;
// 如果有多个return语句,应当跳转回第一个有效的return语句,并移除后续内容
// ...
}
});
}作用域检测
部分函数也可能是死代码,例如,未return,同时也未引用外部作用域的函数,一定是死代码,我们可以通过检查函数体是否引用了外部作用域的变量,移除未引用外部作用域的函数,不过需要注意的是,还需要检测函数是否调用了eval等动态的内容,以及是否对传入的容器类实参进行了修改
FunctionDeclaration(path) {
const { node, scope } = path;
let dependsOnExternalVariables = false;
// 遍历函数体,检查是否依赖外部变量
path.traverse({
Identifier(innerPath) {
if (!innerPath.scope.hasBinding(innerPath.node.name) && scope.hasBinding(innerPath.node.name)) {
dependsOnExternalVariables = true;
innerPath.stop();
}
}
});
// 如果不依赖外部变量,移除整个函数,注意一下,实际的代码需要变通,还需要检测return
if (!dependsOnExternalVariables) {
path.remove();
}
},结果展示
我们的ast反混淆插件一共为520行,我们对5s盾的代码进行多次执行反混淆,直到代码行数不缩减为止,即为反混淆完成

对比一下,仅仅使用了以上几种简单的方案,从5600行到2100行,解混淆后的行数直接缩减到解混淆前的37%,此外代码的可读性也大大增强了,所以说ast这个大杀器,一定要牢牢掌握

还原后的
S[0] = this.h51 ^ this.g ^ this.h51 ^ this.g"charCodeAt" - 36 + 256 & 255 | ((this.h51 ^ this.g ^ 220 + this.h51 ^ this.g"charCodeAt" & 255.32) << 16 | (this.h51.37 ^ this.g ^ this.h51 ^ this.g"charCodeAt" - 36 + 256 & 255) << 8);
function gr(Vx, Uo, g, K, U, S) {
Vx = { "P": 512, "g": 1300, "K": 1183, "U": 559, "S": 1489, "N": 675, "c": 1100, "O": 829, "W": 569, "e": 682, "l": 1300, "V": 626, "n": 512, "a": 1187, "s": 675, "Z": 1100, "v": 512, "k": 512, "T": 626, "o": 569, "I": 1386 }; g = { "JFNhS": function (N, c) { return N ^ c; }, "BRFeX": function (N, c) { return N - c; }, "rnPVe": function (N, c) { return c | N; }, "iOnWg": function (N, c) { return N ^ c; }, "sKoCN": function (N, c) { return N & c; }, "sCcBs": function (N, c) { return N + c; }, "VgGZa": function (N, c) { return N - c; }, "PIAbk": function (N, c) { return N ^ c; }, "ECJOB": function (N, c) { return N ^ c; }, "mmyDy": function (N, c) { return N - c; } }; K = g; debugger; U = g["JFNhS"](this.h[51 ^ this.g][3], g["BRFeX"](this.h[this.g ^ 51.12][1]["charCodeAt"](this.h[this.g ^ 51][0]++), 36) + 256 & 255.9) ^ 226.49; S = this.h[g["JFNhS"](51, this.g)]["slice"](); S[0] = g["rnPVe"]((this.h[g["JFNhS"](51, this.g)][3] ^ 220 + this.h[g["iOnWg"](51, this.g)][1]["charCodeAt"](this.h[g["iOnWg"](51, this.g)][0]++) & 255.32) << 16 | (this.h[51.37 ^ this.g][3] ^ g["sKoCN"](g["sCcBs"](g["VgGZa"](this.h[g["JFNhS"](51, this.g)][1]["charCodeAt"](this.h[51 ^ this.g][0]++), 36), 256), 255)) << 8, g["PIAbk"](this.h[51 ^ this.g][3], g["sKoCN"](g["sCcBs"](this.h[g["JFNhS"](51, this.g)][1]["charCodeAt"](this.h[51 ^ this.g][0]++) - 36, 256), 255))); S[3] = g["ECJOB"](this.h[51.39 ^ this.g][3], g["sCcBs"](g["mmyDy"](this.h[this.g ^ 51][1]["charCodeAt"](this.h[51.56 ^ this.g][0]++), 36), 256) & 255.74) ^ 129; this.h[g["JFNhS"](U, this.g)] = rj["bind"](this, S);}
S[0]的赋值, 对同一个数组元素进行多次++操作, AST还原后会改变执行顺序, 结果对不上 .
佬儿有遇到这个吗
涉及对变量和对象成员进行单目运算的部分,一般不建议直接还原