腾讯这次还是挺狠的,直接把栈式虚拟机更新成寄存器式虚拟机了,并且将原先的60多条指令膨胀到80多条。栈式虚拟机的指令集通常较为简单,指令操作主要围绕栈进行,由于栈式虚拟机的广泛使用,现有的资料对栈式虚拟机的支持较为成熟。而相比于栈式虚拟机,寄存器式虚拟机的指令集复杂,我们需要处理更多的指令类型和寄存器操作,不过对于web虚拟机来说,其功能本质仍旧是对js内存空间的访问。两个月前才刚刚完成了旧vmp逆向,这下直接在风中凌乱……好吧,那只能我们继续重新分析了
我们的目标
实现反编译器,通过传入原始jsvmp程序,生成汇编

最后生成js代码并保证运行逻辑一致
//将 类似"JgQCFhoEBBZEHgASPkQEZp/4A4PzAg=="的jsvmp程序 还原成下方的js代码
locals[11] = "__lastWatirConfirm"虚拟机入口
vmp部分共计800行,腾讯的vmp样例还是比较清晰的,整段代码没有太多无用的混淆,而仅仅用了一个朴实无华的vm
我们将短的函数进行一下折叠,查看一下代码结构,可以看到整个vm由一个大的控制流和一些函数组成,向下寻找,找到缩进最多的地方,虚拟机的解释器通常通过循环和流程控制语句嵌套构成,因此会形成较多的缩进

其中最内层的switch控制了整个流程的执行,整个虚拟机结构较为经典,为while-switch结构,没有多余的if或逻辑表达式混淆

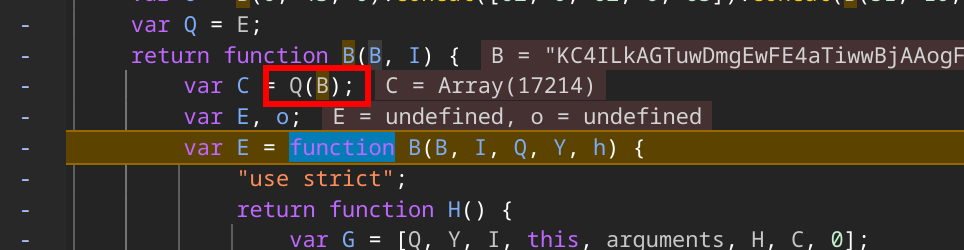
查看switch顶部,查看switch的条件由整个C数组控制,说明C就是传入的程序字节码,我们需要知道C数组的生成方式

进入浏览器的devtools,打上断点,刷新执行一下,发现C数组是由传入的B参数经过Q函数生成的,Q函数实际上会经过别名赋值,跳转到E函数,因此E就是我们需要解决的字节码还原算法了。
程序加载器解密
变长编码控制流
查看一下E函数的编码方式,每次循环中,都会读取一个字节 a,并将其与 127 进行按位与操作,得到 o

事实上,大部分被混淆后的算法,都是来源于通用算法,总是有迹可循的。例如,base64编码算法通常要大量操作 0-9\a-z\A-Z\= 这些字符,urlencode会大量操作 %,变长字符串编码通常会通过分组拼接方式来完成字节生成,因此我们只要找到对应的特征,就能知道他使用了什么解密算法。
例如,上图有一个比较明显的重复操作,即每轮都会将从B数组取出的8位int的低7位(通过和127 按位与运算来实现),并将其和o拼接,如果 a 的最高位(第8位)为 0(即 a >= 0),则表示这是一个单字节的值,直接将 o 通过 C 函数处理后存入 g 数组,并继续下一次循环。
这种操作很像是在处理变长整数编码(如 varint 编码),在这种变长整数编码方式中,每个字节的最高位用于指示是否有后续字节,并指示需要将多少个字节拼接为一个整数。不过只靠这些信息我们还是很难看出他在做什么,因为while循环体内的流程被扁平化了,实际上有4个if和continue对执行流程进行了控制,需要我们进行一下还原。
看一下,这里在每个if的代码块中,存在一个continue,这意味着如果id的条件为真,就不再执行后面的代码,因此我们可以将后面的代码块看作是else分支
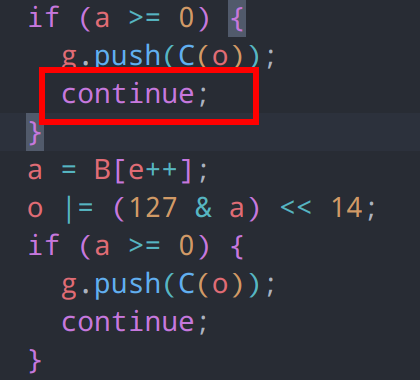
因此我们第一步就可以将控制流代码还原成这样

接下来看一下,在每一个else分支中,都通过B[e++]的形式拿到了数组的下一个8位int,并将其低 7 位左移 7 位后与 o 进行按位或操作,这一步的作用是增加o的位数长度。重复上述步骤,直到读取到一个最高位为 0 的字节。每一步的操作都和最开始的if分支操作相同,但是会将字节进行移位处理,并重复将a合并为到o中。因此可以将其简化为一个循环
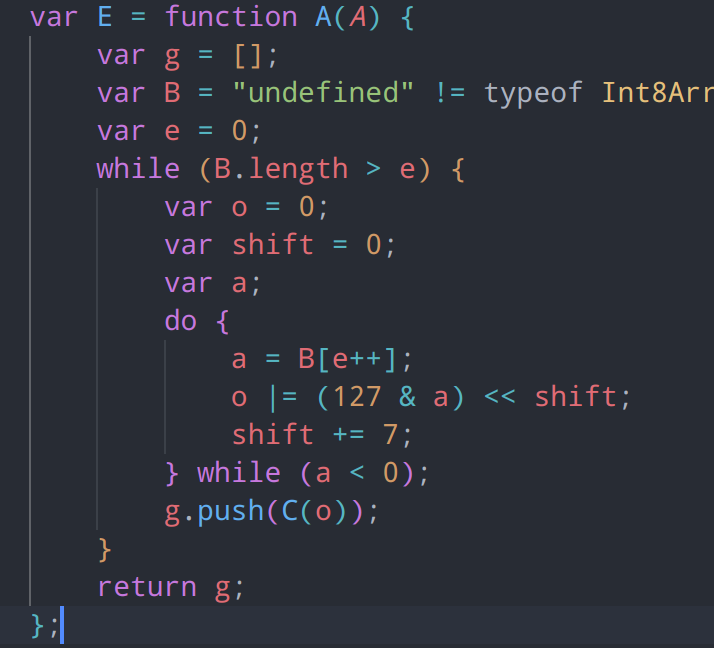
在上面的操作中,我们已经分析了,在变长编码中,每个字节的最高位用于指示是否有后续字节,最高位为0时,代表这个数结束了,所以说明E 函数很有可能实现了一个变长整数解码器,并将解码后的整数存储在数组 g 中
ZigZag编码特征
在将o插入g数组前,每个整数还通过 C函数进行了处理,看上去像是一种通用的算法,百度一下,果然,(A >> 1) ^ -(1 & A) 这种表现形式实际上是一种叫做 ZigZag 编码的解码算法,ZigZag 编码是一种将有符号整数编码为无符号整数的方法,使得绝对值较小的负数和正数都能使用较少的字节表示,从而提高编码效率。
var C = function A(A) {
return (A >> 1) ^ -(1 & A);
};那么现在还剩下B数组的生成方式未知了,B数组由传入的Base64编码通过I函数生成,I函数实际上是将一个 Base64 编码的字符串转换为一个字节数组。它首先将输入字符串去掉尾部的等号,然后将每个字符转换为对应的 Base64 索引值,最后将这些索引值组合成字节数组。

双虚拟机结构分析
加载器
折叠函数内容,可以看出vm的初始化流程
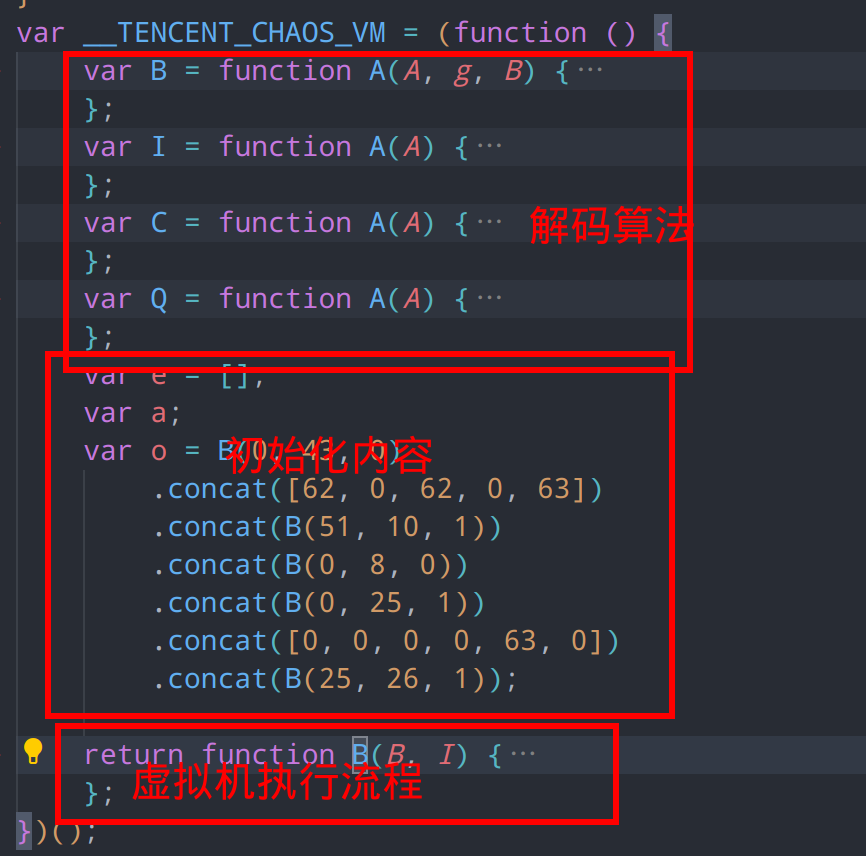
我们在前文得知,程序码的加载过程是
- 将传入vmp的Base64字符串先解码成无符号int8数组,这个int8数组实际上储存的是一段ZigZag编码
- 通过E函数,将ZigZag编码的无符号整数数组,还原成正常的有符号指令数组
按照上面的流程把程序加载器提取出来,去除混淆,并删除原始代码,我们就得到了程序加载器

解释器
查看虚拟机结构,发现里面居然有两个不同的vm执行流程,通过传入的参数I来控制具体执行哪个流程

通过对参数寻找,我们很轻易地发现了传入的参数会使条件表达式I ? E : o 恒为假,因此,此虚拟机的执行流程中很有可能不执行E流程

然而,不幸的是,我们发现o和E这两个虚拟机是相互调用的,因此,return的条件表达式只能代表o为入口虚拟机,这一下就亚历山大了,这代表我们需要同时对两个vm进行分析

将两个虚拟机的解释器部分提取出来,进行文本比对,发现居然完全一致,说明两个虚拟机的指令完全是相同的

观察两个虚拟机,发现二者只有"use strict"的区别
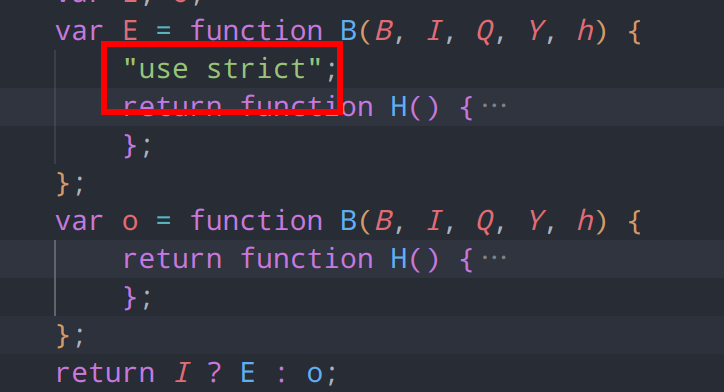
"use strict" 是 JavaScript 中的严格模式,它会对代码的执行施加更严格的限制,在 ES6 中,严格模式也可以在块级作用域中生效,因此两个虚拟机的区别仅仅是是否启用严格模式
{
"use strict";
// 这个块级作用域在严格模式下运行
function example() {
// 这里也是严格模式
}
}
// 这里不是严格模式在严格模式下能够运行的代码,那么一定能在非严格模式中运行,因此我们将非严格模式的虚拟机代码删除,仅保留严格模式,利用抓包软件的重写功能替换响应,执行一次试试

结果正常返回了内容,因此,我们仅需保留任意一项虚拟机代码
虚拟机的实现必定会有栈、PC计数器、以及程序代码,这一步我们可以将疑似栈、PC计数器、以及指令码的变量先标识出来,以便分析
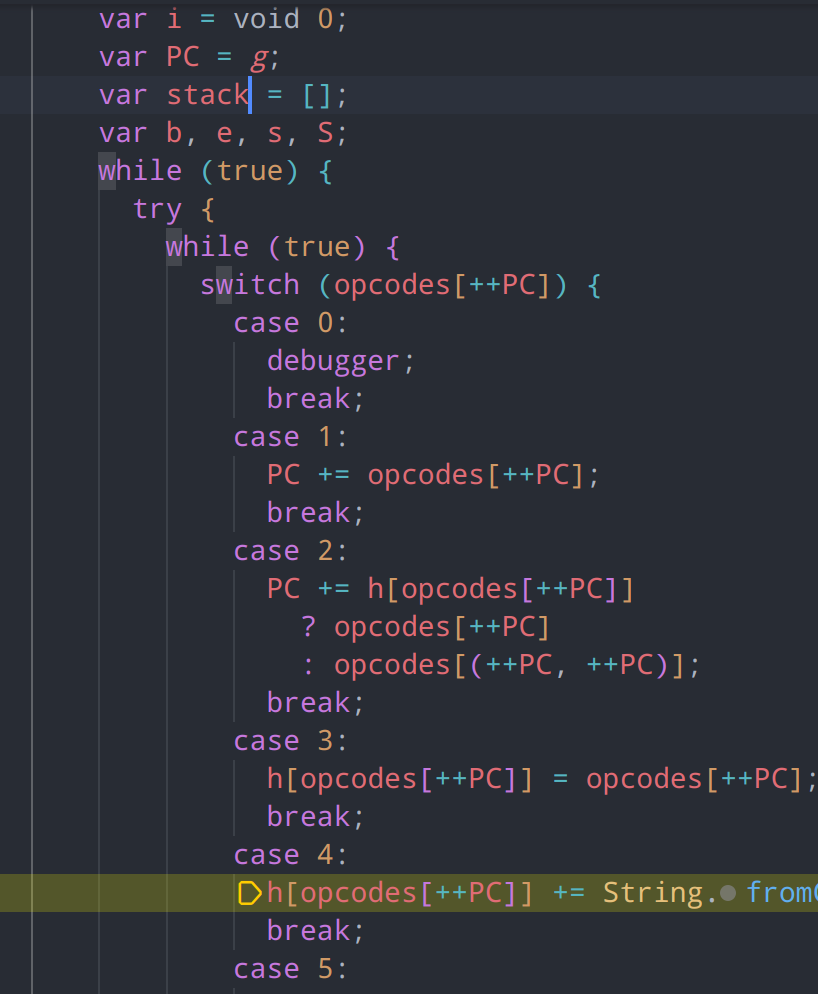
变量还原后,可以看到case内有大量的opcodes[++PC],这代表一条case指令在执行时还会获取多个连续的操作数,每获取一个会将PC计数器指向的程序地址+1,类似OP R1, R2, R3
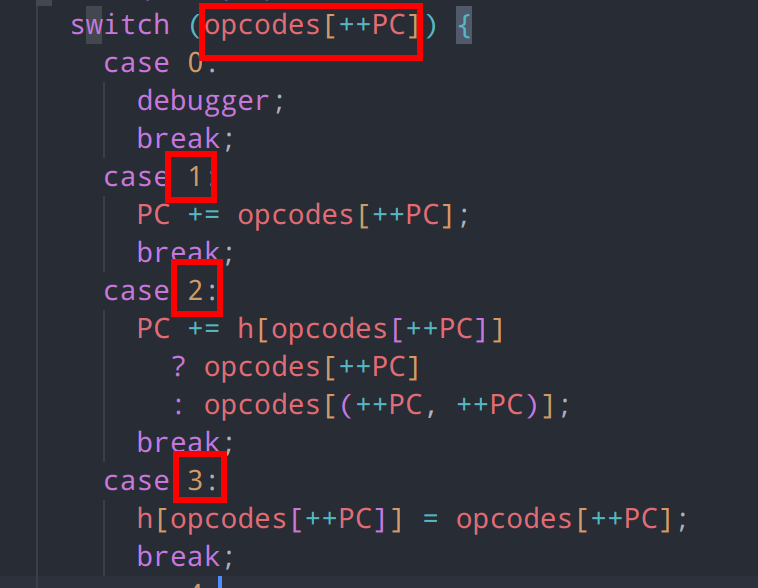
查看代码,未发现明显的栈操作,且stack.pop()在执行时并未将出栈操作数保存下来

这让我们联想到寄存器式的虚拟机。寄存器虚拟机使用寄存器来存储操作数和中间结果,而不是利用栈。在执行操作时,虚拟机指令通常同时包含指令码和多个寄存器操作数。例如 ADD R1, R2, R3 表示将寄存器 R2 和 R3 的值相加,并将结果存储在寄存器 R1 中。
回想一下我们之前遇到的栈式虚拟机,在进行二元操作时,是什么样子的
var _0x4db217 = _0xcc6308[_0x2e1055--]; //栈顶弹出操作数
_0xcc6308[_0x2e1055] = _0xcc6308[_0x2e1055] + _0x4db217; //和栈顶相加并重新放回栈内而我们现在看到的样本代码的运行方式是在获取到指令码后,再连续读取和指令相关的寄存器进行操作,和我们遇到的栈式虚拟机特征完全不符合,其行为反而非常符合寄存器式虚拟机的执行方式,因此我们怀疑这个虚拟机为寄存器式虚拟机,h可能为寄存器保存区域。
在所有二元表达式的地方输出记录,打印获取h的下标

替换浏览器端代码后执行一下。输出结果表明,在二元运算中,的h的下标是固定的,二元运算从h[17]、h[22]取出值进行运算后,再存回h[26]的固定位置。这代表着h[17]、h[22]、h[26]是加法运算的寄存器,证实了我们的猜想。因此,我们可以得出结论,变量h储存了当前执行程序的上下文环境和操作数寄存器,h[index]实际上为获取寄存器值的操作,而opcode[++PC]为指令后的操作数
callback栈
查看catch分支,此处为异常处理流程
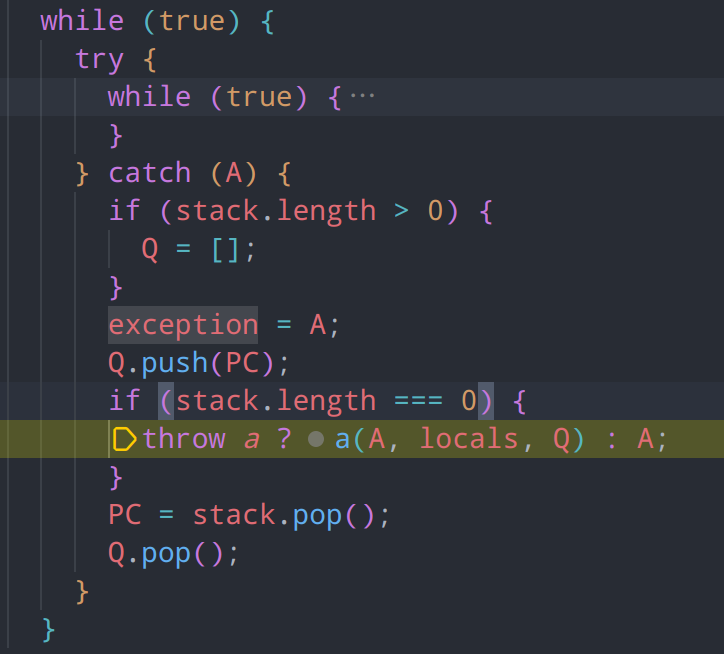
- 当虚拟机执行过程中发生异常时,
catch块会捕获该异常。 - 将异常对象
A保存到exception变量中。 - 如果
stack不为空,表示当前有未完成的函数调用,需要返回上一个调用点继续执行。 - 如果
stack为空,表示没有更多的调用点可以返回,直接抛出异常。如果提供了异常处理函数a,则调用该函数处理异常,否则直接抛出异常。
注意一下这个入口的a,出现在了catch分支中,并传入了当前的异常、上下文和异常栈,说明这是个异常处理函数,但是并没有在虚拟机中被修改过,传入值也为void 0,可能用于腾讯官方的debugger或日志上报组件

catch分支很重要,对程序当前PC计数器进行了状态保存,因此任何涉及这里的变量更改都要小心注意
指令集
假设当前PC寄存器的指向的命令为MOV,那么 MOV R1,R2,就可以混淆为MOV opcode[++PC],opcode[++PC]
case 3:
h[opcode[++PC]] = opcode[++PC];
break;实际上他的意义是这样的:
// case3为mov命令,将操作数的值赋值给寄存器
case OP.MOV:
// 通过opcode[++PC]获取连续的两个操作数,获取的第二
const value,reg;
value = opcode[PC+1];
reg = opcode[PC+2];
PC += 2;
// 更新寄存器
h[reg] = value;相比于栈式虚拟机的指令集,这个虚拟机的指令集就精简的多了,一共仅有91条指令集,我们需要逐个定义出相应的指令
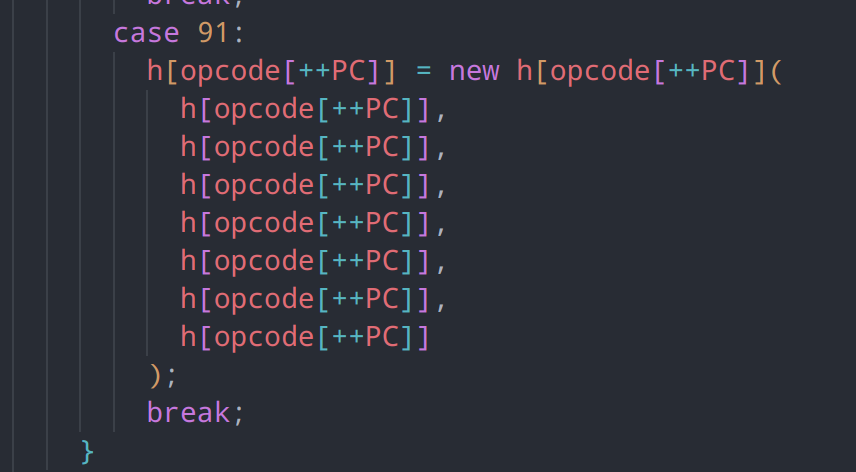
其中大部分的指令集都非常简单,我们可以根据相应的操作,定义出我们的汇编指令
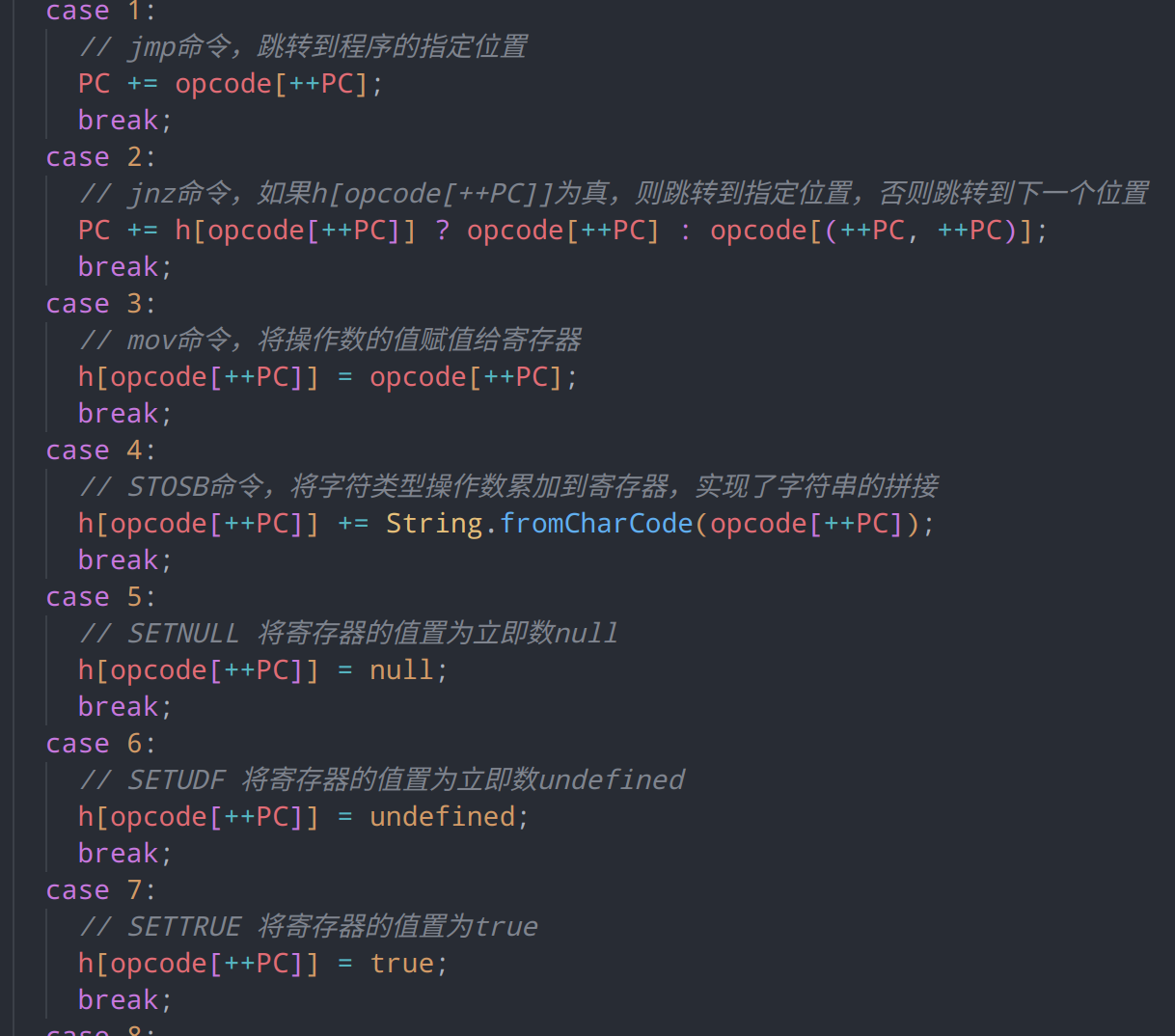
然而,虽然我们知道了整个虚拟机的运行方式和指令集,但我们该如何还原指令集,从而让他更加简单呢?以下面这些二元运算为例,我们虽然知道这段代码的实际意义,但可读性依然较低,我们不知道这些指令对哪个寄存器进行了交互,也不知道汇编指令的参数长度,并且在执行时,还会对PC计数器进行自增,这大大影响了我们的阅读
// 指令阅读起来较为困难
case 18:
e = [];
for (s = opcode[++PC]; s > 0; s--) e.push(h[opcode[++PC]]);
h[opcode[++PC]] = o(PC + opcode[++PC], e, Y, strs, a);
try {
Object.defineProperty(h[opcode[PC - 1]], "length", {
value: opcode[++PC],
configurable: true,
writable: false,
enumerable: false,
});
} catch (A) { }
break;汇编指令通常没有动态的变长参数的概念,每条指令的操作数数量和类型在指令集中是明确规定的,我们可以因此制定一下转换规则
h[opcode[++PC]] = h[opcode[++PC]] + h[opcode[++PC]];
// 可以转换为
h[args[2]] = h[args[0]] + h[args[1]];
PC += args.length并且重新处理一下指令集定义和操作码加载方式
// 定义指令的执行方法
function ADD(arg0, arg1, arg2) {
h[arg2] = h[arg0] + h[arg1];
}
// ...
// 定义指令集
const OP = {
41: ADD,
42: SUB,
43: MUL,
};
// 定义一个指令加载器
function loadOP(opcode) {
const args = [];
for (let i = 0; i < OP[opcode].length; i++) {
args.push(h[++PC]);
}
OP[opcode](...args);
}这样子我们就将指令集、指令定义、解释流程抽离开来了
// 解释器
while (true) {
loadOP(opcode[++PC])
}指令抽取
还原思路
我们重新定义了解释器的执行方式,下一步需要将case 41的节点转换为如下的形式,以便于未来再次转换成汇编语言
// 指令操作方式
function ADD(args) {
h[args[0]] = h[args[1]] + h[args[2]];
}
// 指令集定义
const OP = {
41: { code: 41, name: 'ADD', func: ADD, argnums: 3 }
}比较困难的是,部分指令需要重新理解他的意义,例如指令10的作用,将一个值减去 0 可以强制将该值转换为数字类型,此处的意义实则为强制将任意类型转换为Number类型而并非是算术运算
case 10:
h[opcode[++PC]] = h[opcode[++PC]] - 0;
break;此外opcode[++PC]在还原为args[0]的形式时,PC的偏移量也要和js的运行时执行逻辑完全一致,在下面这个例子里,条件表达式的条件未知,因此PC在程序执行完毕后的偏移量可能为2和3两种情况。
case 2:
PC += h[opcode[++PC]] ? opcode[++PC] : opcode[(++PC, ++PC)];
break;我们在进行ast还原时,还需要注意优先级
js表达式求值特性
这里有一个js的坑点,导致我第一次进行节点还原时完全还原错了,浪费了一天的时间排查问题:js在进行表达式求值的时候直接按照ast树顺序向下求值,也就是从左向右向求值,而不是像其他语言一样严格遵需从内向外的执行顺序
h[opcode[++PC]][h[opcode[++PC]]] = h[opcode[++PC]];举个例子,在其他语言中,表达式的求值顺序是按照语句执行的优先级,从内向外求值。上面的这行语句,在python中会遵循如下的运行逻辑:
- 赋值表达式右侧先于左侧执行,因此赋值表达式右侧的
opcode[++PC]应当是args[0] - 成员表达式外层先于内层执行,因此赋值表达式左侧应当是
h[args[1]][h[args[2]]] - 从左往右的参数顺序是
args[1],args[2],args[0]
而Js中,表达式的求值顺序是从左向右
- 因此,从左往右的参数顺序是
args[0],args[1],args[2]
function value(index) {
console.log("value("+index+")执行")
}
a[value(0)][value(1)]+=a[value(2)]+value(3)上面这行代码的输出结果是:
value(0)执行
value(1)执行
value(2)执行
value(3)执行而在python中的输出结果是:
value(2)执行
value(3)执行
value(0)执行
value(1)执行可以看到在第一次进行还原时,我按照语句的执行顺序进行求值,导致还原出的参数顺序完全错了,事实上在赋值语句左侧的参数应该还原为arg0
抽取思路
不过,纯粹按照从左向右的顺序,反而更好还原了,因为我们只需要遍历ast树,而不需要关注具体的执行逻辑
我们先将所有的case分支利用ast提取出来,并移除掉break语句,将其合成为函数列表
//提取为函数
traverse(ast, {
SwitchStatement(path) {
path.node.cases.forEach(caseNode => {
const caseCode = caseNode.test.value;
const funcName = t.identifier("op_" + caseCode);
for (const statement of caseNode.consequent) {
if (t.isBreakStatement(statement)) {
caseNode.consequent.pop();
}
}
const funcBody = t.blockStatement(caseNode.consequent);
const func = t.functionDeclaration(funcName, [], funcBody);
program.body.push(func);
});
}
});
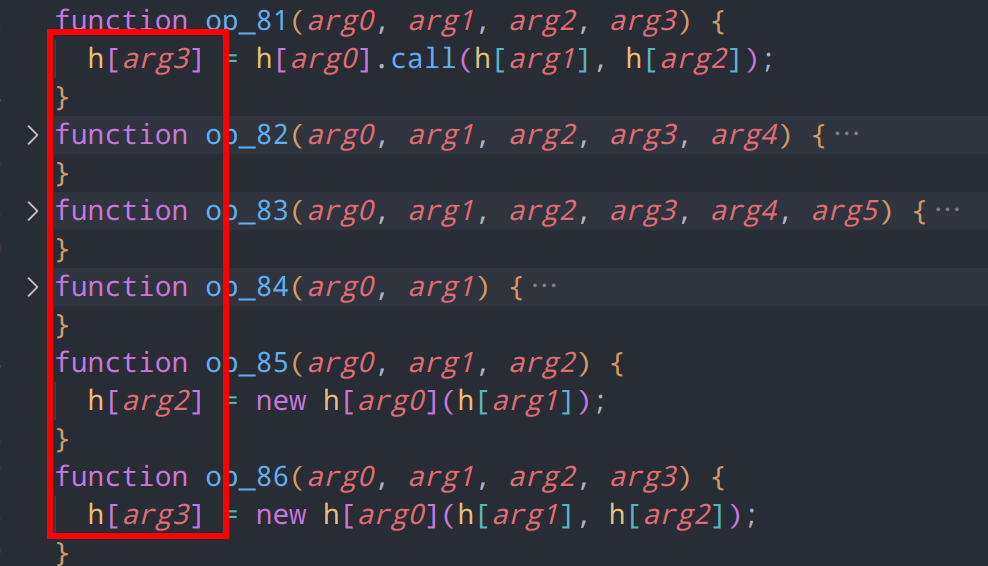
利用ast进一步转换,将其形参和实参对应上,很快便将大部分参数个数和顺序还原了
还剩一些由于内部含有控制流,从而导致参数可能为变长参数,这种情况下我们暂时不要对参数直接进行处理
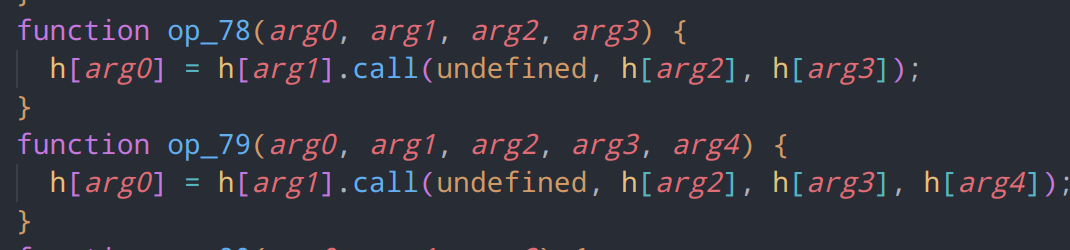
op18和op19,实际上为同一内容,作用是导入变长参数并执行一段vmp函数,将返回结果储存在寄存器中

函数调用,调用js函数,并传入一段上下文
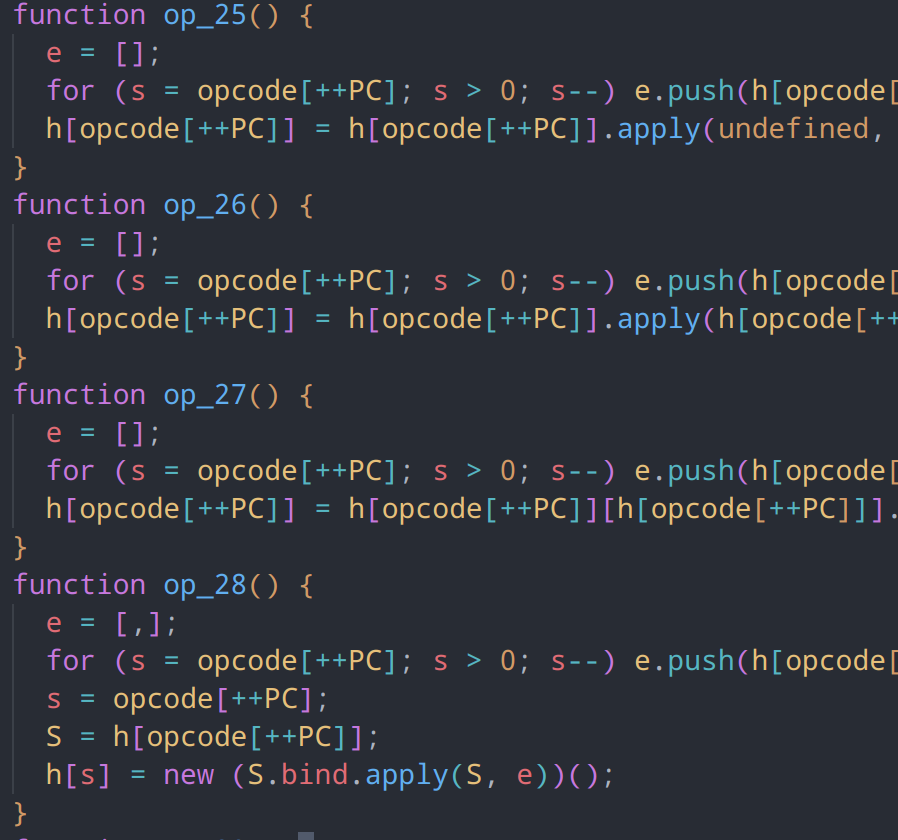
归并节点
为了更好处理指令,我们在指令节点加上注释
case 1:
// jmp 命令,跳转到程序的指定位置
PC += opcode[++PC];
break;部分节点暂时不知道用处的,可以暂时标记为unknown命令
case 28:
// __unknown 疑似new操作
e = [,];
for (s = opcode[++PC]; s > 0; s--) e.push(locals[opcode[++PC]]);
s = opcode[++PC];
S = locals[opcode[++PC]];
locals[s] = new (S.bind.apply(S, e))();
break;还原一下部分变量名,如 h 我们可以先设为 locals,以待后面分析
通过 leadingComments 获取节点的注释,修改为我们设置的方法名,最后生成节点,归并入对象中储存
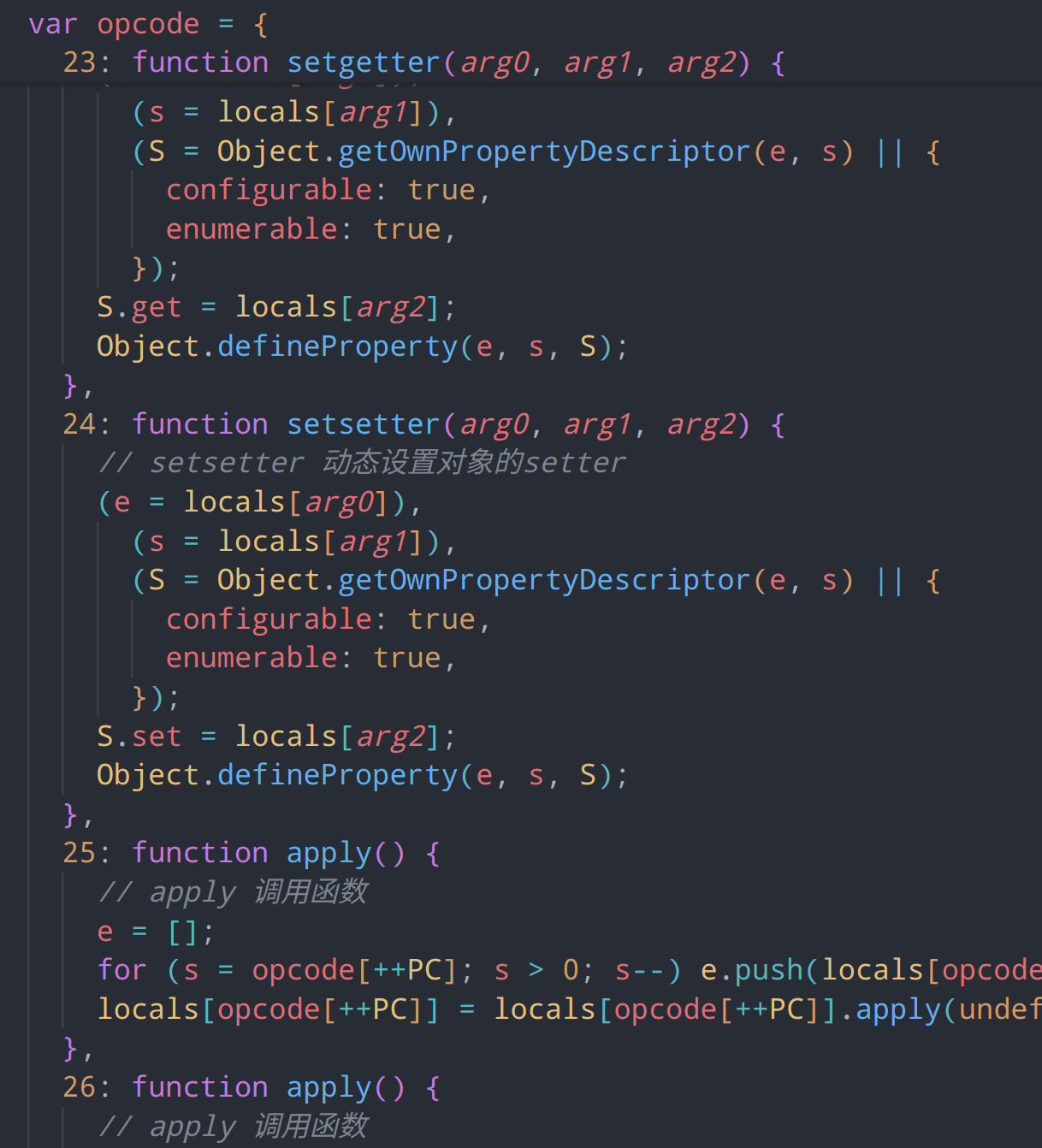
部分指令其实仅有参数长度的区别,因此我们可以使用同一个指令名

不明的指令我们使用unknown_指令码的方式来代替

参数类型标注
在汇编语言中,立即数(Immediate Value)是指在指令中直接包含的常数值。立即数是指令的一部分,通常用于指定操作数的值,而不是引用内存地址或寄存器中的值。
// 检测参数类型并替换名称
if (innerPath.node.object.name == "opcode") {
let idName = "imm" + immCount
immCount += 1
if (t.isMemberExpression(innerPath.parent)) {
const objName = innerPath.parentPath.node.object.name
if (objName == "locals") {
idName = "R" + regCount
regCount += 1
immCount -= 1
}
}
const id = t.identifier(idName)
innerPath.replaceWith(id);
path.node.params.push(id);
}还原一下参数类型,表示寄存器的类型使用R来替代,立即数用imm替代,方便我们后续生成汇编

接近100条指令仅用8条未知,在后期运行时再进行分析
又一个js“特性”
抱着侥幸心理,将我们编写的简易版指令执行器替换腾讯vmp的executor,运行一下,果然报错
这时候需要插桩查看一下问题了,发现js运行时报错出现在jmp指令之后。我们的jmp命令执行完毕后,PC计数器的值会比原版多+1,所以导致本应在下一条执行的字节码18变成了字节码1

这不得不说是令人费解的,因为我们的jmp命令仅仅是将js代码包装进函数罢了
// 包装前流程
PC += opcode[++PC];
// 包装后执行流程
arg0 = opcode[++PC]
PC += arg0;实际上,这还是js的“特性”,执行以下代码,你可以发现,第一次输出的PC为3,第二次则为4
var PC = 1
PC += ++PC
// PC = 3var PC = 1
var value = ++PC
PC += value
// PC = 4我们将这段代码编译为v8字节码
var PC = 0;
PC +=1; 0x63e081d5b7a @ 0 : 0c LdaZero
0x63e081d5b7b @ 1 : 25 02 StaCurrentContextSlot [2]
0x63e081d5b7d @ 3 : 17 02 LdaImmutableCurrentContextSlot [2]
0x63e081d5b7f @ 5 : 45 01 00 AddSmi [1], [0]
0x63e081d5b87 @ 13 : c4 Star0
0x63e081d5b88 @ 14 : a9 Return LdaZero:将常量0(PC的值)加载到累加器(Accumulator)中。StaCurrentContextSlot [2]:将累加器中的值存储到当前上下文的槽位2中。LdaImmutableCurrentContextSlot [2]:将当前上下文槽位2中的不可变值加载到累加器中。AddSmi [1], [0]:将累加器中的值与小整数(Smi)1相加,并将结果存储在累加器中。Return返回累加器中的值
看出什么端倪了吗?在第一条字节码中,就已经获取了PC的值,并将其存入累加器,这意味着累加时,赋值语句左侧的PC一直是最初的值
PC += ++PC 实际上等同于 PC = (PC)+(++value),变成了简单的覆盖操作,而不是在右侧表达式执行完毕后再进行累加
因此对于 jump 和 jump_zero 命令这类会对PC计数器进行累加的命令,我们有两种操作思路,第一种即不将参数提取出来,这样指令操作就和原本的执行顺序一模一样了
function jmp() {
PC += opcode[++PC];
}第二种则是手动对PC结果进行处理
环境污染
运行到第94756行的时候,发生了一个问题,此处为RET指令,代表结束当前虚拟机并返回寄存器的值,然后恢复PC计数器的值,然而两份代码在该条命令结束后,PC计数器的值却并不相同
腾讯原始代码在结束后,PC回到了18796

我们的代码在结束后仅仅是将PC后移1位(此处两位是因为还有一位是读取的指令参数)

在虚拟机执行函数时,程序计数器(PC计数器)是一个关键的组件,它用于跟踪当前正在执行的指令地址。当虚拟机准备执行一个函数时,它通常会将当前的PC计数器值保存到一个调用栈中,以便在函数执行完毕后能够返回到调用点。在进入vmp函数时,虚拟机会将PC计数器设置为被调用函数的入口地址。当函数执行完毕时,虚拟机会从调用栈中弹出先前保存的PC值,并将其恢复到PC计数器中,从而使得虚拟机能够返回到函数调用点并继续执行后续指令。因此,PC计数器几乎没有可能在RET命令执行后依旧仅作+1递增,这意味着ret没有跳出当前函数。
回顾一下之前提取的指令集,似乎并没有恢复PC计数器状态的指令。观察代码,代码中的PC是由每一次vmp初始化时传入的,仅需要return出下层函数,就能恢复上层PC计数器的状态。因此PC计数器的保存是由JS的闭包实现的,我们实现的执行器,可能造成了上下文环境污染,从而使外层闭包的PC值出现问题

问题定位到这里,我们的执行器在执行指令的时候,传入了this,this在严格模式下,为undefined,在非严格模式下为global或window,由此造成了环境的污染
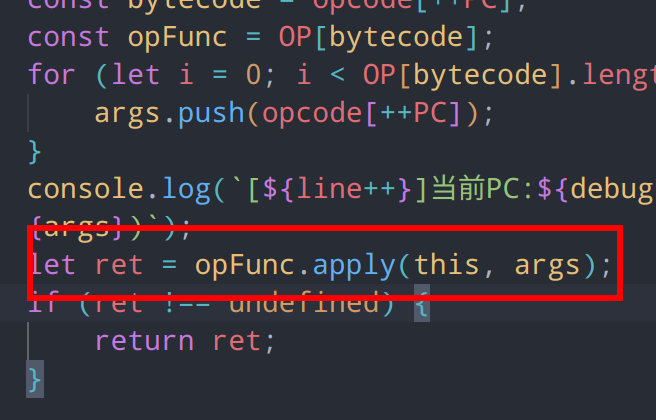
将其改为opFunc.apply(undefined,args)或opFunc(..args),执行正常。
接着运行,发现还是有ret不跳出的问题,再次观察,发现我们对于能否跳出当前vmp的设定出了些问题
let ret = opFunc.apply(undefined, args);
if (ret !== undefined) {
return ret;
}当bytecode为16时,说明当前为ret指令,然而ret也是可以返回undefined的,因此做如下修改
if (bytecode === 16) {
return ret;
}重新运行,最终在执行了88万条汇编指令后退出了虚拟机

反编译
反汇编
此时,我们通过编写代码拥有了
- 程序加载器:用于加载虚拟机程序代码,并解密为虚拟机字节码
- 指令集:对于虚拟机指令的定义,以及每个指令的参数元数据
除此之外,我们还拥有
- vmp代码、常量、初始环境设定
- 反混淆后的解释器
现在我们可以建立一个反汇编器disassembler对程序代码进行反汇编以深入研究了
分别建立program.b64, program.bin, program.asm, program.ir,四个文件,用于表示原始程序base64、解密后的二进制字节码、汇编asm、用于生成反编译目标代码的中间语言ir
提取vmp程序代码
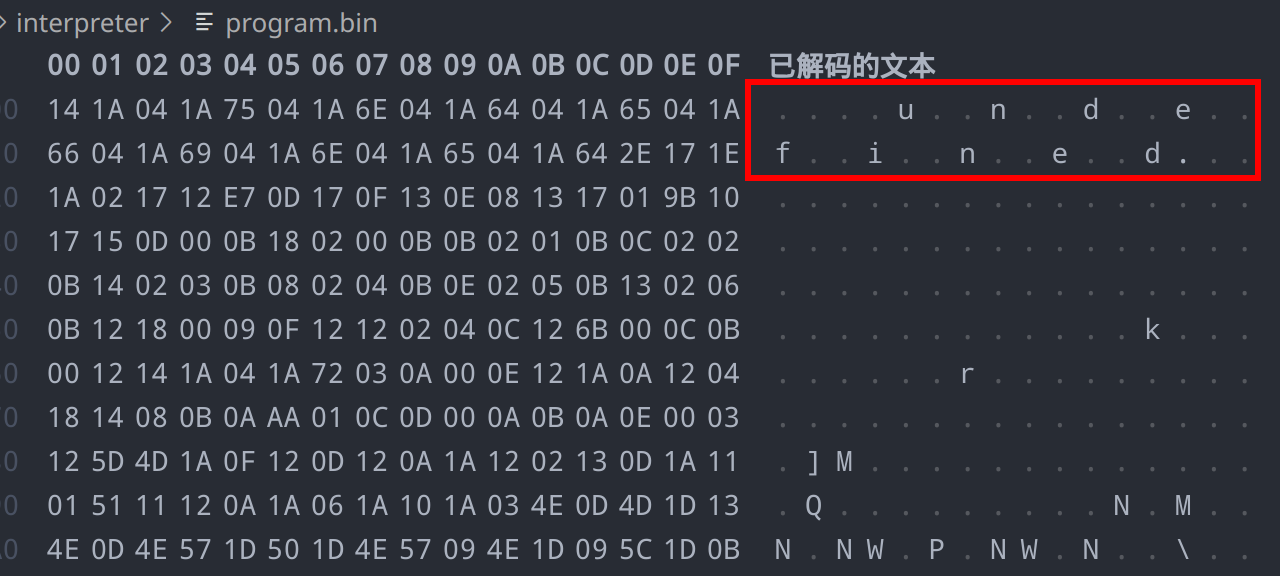
解密为vmp字节码,一共有48000条字节码,可以看到,在程序部分固定的内存空间中实际上含有不少常量,这符合二进制程序的设计
依据之前定义的指令集表instructions.js,编写一个静态反汇编器disassembler,分析出汇编代码

最后转为汇编指令,输出指令地址、指令、参数值等,我们可以看到这个程序一共含有14000条汇编指令,并明确了地址、参数和指令,相比48000条字节码的分析难度小了不止一点

此处展示的是一个低级的反汇编器,仅用于演示。实际上对于开发人员来说,我们还能为其添加更多的反汇编功能
- 例如,
locals中的寄存器实际上是代表不同角色的,我们这里并没有进行深入分析,仅用locals的下标进行标注; - vmp初始化时加载了大量常量进入内存空间,可以通过静态分析将大量的寄存器内容还原为常量
- 我们可以新增一部分伪汇编指令,部分低级汇编指令可以合并为我们新增的高级汇编指令以方便阅读
- 缺少汇编编译器,我们对汇编代码的修改无法还原为程序字节码以进行动态调试分析
到这一步,我们就可以通过对汇编的分析,还原出他的部分js代码了,到这里我们讲解一下目标代码生成的思想
由于其中还含有大量的常量操作,我们可以进一步缩短汇编指令,例如,我们定义的STOSB共有5300条,占据了汇编代码的1/3,假使能将这些汇编指令合并为js代码,是否能够消除我们的分析量呢?

查看一下相对应的汇编代码
45148 SETEMP [11]
45150 STOSB [11,95]
45153 STOSB [11,95]
45156 STOSB [11,108]
45159 STOSB [11,97]
45162 STOSB [11,115]
45165 STOSB [11,116]
45168 STOSB [11,87]
45171 STOSB [11,97]
45174 STOSB [11,116]
45177 STOSB [11,105]
45180 STOSB [11,114]
45183 STOSB [11,67]
45186 STOSB [11,111]
45189 STOSB [11,110]
45192 STOSB [11,102]
45195 STOSB [11,105]
45198 STOSB [11,114]
45201 STOSB [11,109]
45204 SETMEMBERIMM [15,222,11]回忆一下我们对SETEMP和STOSB的定义,不难看出,SETEMP和STOSB同时出现时,实际上的意义为从 常量 声明一个字符串变量。SETEMP先在寄存器11开辟了一个空的内存空间,然后再创建了一个字符串,最后通过SETMEMBERIMM赋值给某个寄存器内obj的成员完成变量声明
function stosb(R0, imm0) {
locals[R0] += String.fromCharCode(imm0);
}为什么我们能认定这个字符串是从常量声明而不是从寄存器中取得的呢?还记得我们之前将参数类型分为R类型的寄存器参数和imm类型的立即数参数吗,立即数类型的参数,是从程序代码中直接提取的,其自身必定为常量
因此,上述的代码可以优化为
const asciiValues = [
95, 95, 108, 97, 115, 116, 87, 97, 116, 105, 114, 67, 111, 110, 102, 105, 114, 109
];
const result = asciiValues.map(value => String.fromCharCode(value)).join('');
// 输出: "__lastWatirConfirm"
locals[11] = resultNFA模式匹配
利用NFA,我们可以像正则一样去匹配符合模式的汇编代码块,首先编写一个nfa

定义状态间的转换方式
定义拓展指令集,从999开始,用于缩短汇编代码

进行反汇编,可以看到我们的汇编代码已经将指令合并好了

由于传入的立即数参数均为常量,因此可以进一步优化为如下形式,这样我们就得到了一份js代码
locals[49] = "Map"汇编控制流还原
低级别的机器码或汇编代码转换回高级别的源代码目标语言的过程,就叫做“反编译”(Decompilation)。通过这种方式,我们就可以将汇编还原为原始代码,我们的这个例子中通过对立即数操作的分析,就完美找到了字符串声明的逻辑。其他的,如JMP、CALL、RET 等指令则可以揭示程序的控制流结构,通过分析函数调用和返回的模式,可以推断出函数的参数和返回值。能否掌握反编译jsvmp的技术,就看逆向人员对编译原理的理解了。
例如,在汇编代码中,我们可以看到以下几个指令序列:
#Block_6961
6961 GETMEMBERIMM R44, R18, 0
6965 CALL R26, R44, R50
6969 EQ R23, R30, R26
6973 JNZ R23, 35380, 28425这里的 EQ 指令用于判断两个寄存器的值是否相等,随后的 JNZ 指令根据条件跳转到不同的代码块。这可以还原为以下 JavaScript 代码:
if (R23 === R30) {
// Block_35380
} else {
// Block_28425
}汇编代码中有如下一段:
#Block_201
201 MOVREG R23, R19
204 ASNUM R10, R23
207 INC R23, R23
210 MOVREG R19, R23
213 LT R38, R19, R12
217 JNZ R38, 37, 27169这里使用 LT 指令检查寄存器 R19 是否小于 R12,然后根据条件跳转到不同的代码块。这可以还原为以下 JavaScript while 循环:
while (R19 < R12) {
// Block_37
R19 = R23;
R23 += 1;
}
// Block_27169汇编代码中也有类似的循环结构:
#Block_1031
1031 GETMEMBERIMM R18, R2, 0
1035 GETMEMBERIMM R11, R18, 0
1039 MOVREG R13, R11
1042 GETMEMBERIMM R11, R4, 1
1046 GTIMM R21, R11, 0
1050 JNZ R21, 21297, 17955这里使用 GETMEMBERIMM 指令获取寄存器 R2 和 R4 中的值,然后通过 GTIMM 指令检查条件,最后根据条件跳转到不同的代码块。这可以还原为以下 JavaScript for 循环:
for (let R13 = R11; R11 > 0; R11 = R18) {
// Block_21297
}
// Block_17955利用我们的nfa,我们可以尝试还原出原始的 JavaScript 代码结构,包括 if-else 语句、while 循环和 for 循环等。这些还原的过程需要仔细分析每个指令的语义和寄存器的用途,以确定正确的控制流结构

最近发现可以让大模型直接反汇编,,发现蛮好用,作者也可以试下,可以用ast抽出每个opcode,然后告诉大模型谁是pc,谁是stack啥的,让他写一小段代码,
要掌握 JavaScript 虚拟机去虚拟化,应该学习哪些主题? 这是我找到的关于这方面最好的资源.
js基础和任意一门汇编基础,重点是熟悉编译原理,需要懂得虚拟机的运作方式
催更一下,怎么还原成js呢?
直接用ast还原太吃力了,控制流不好判断啊
还有后续么,还原成 js 的过程,期待。
近期在找工作,可能要等很久了,后面会分享一些思路。目前来说这篇文章的还原方式实际上是比较吃力的,只是更加契合虚拟机正向开发的思路,利用ast的还原方案较为方便
对于该项目的完成,我想了解这个 javascript 脚本的来源,是否还是tdc.js,或是其他